Monday, 11th August 2025
Chromium Docs: The Rule Of 2. Alex Russell pointed me to this principle in the Chromium security documentation as similar to my description of the lethal trifecta. First added in 2019, the Chromium guideline states:
When you write code to parse, evaluate, or otherwise handle untrustworthy inputs from the Internet — which is almost everything we do in a web browser! — we like to follow a simple rule to make sure it's safe enough to do so. The Rule Of 2 is: Pick no more than 2 of
- untrustworthy inputs;
- unsafe implementation language; and
- high privilege.
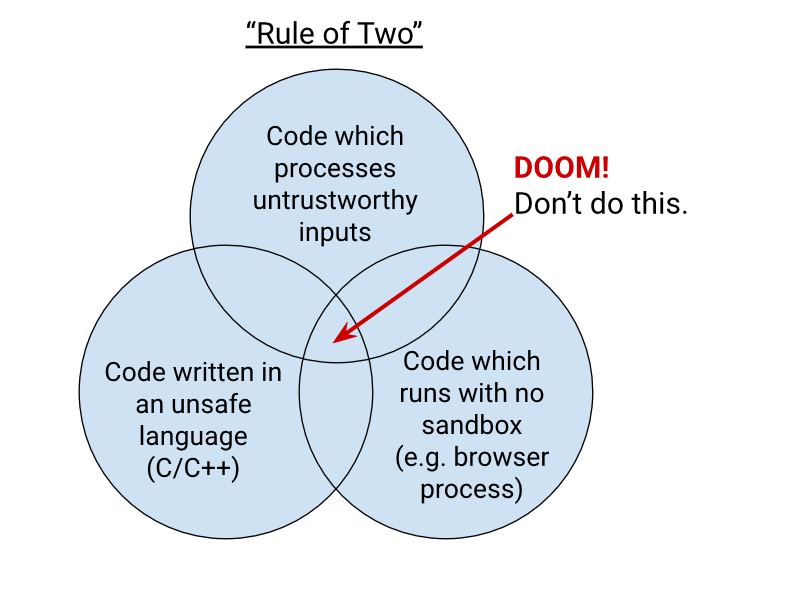
Chromium uses this design pattern to help try to avoid the high severity memory safety bugs that come when untrustworthy inputs are handled by code running at high privilege.
Chrome Security Team will generally not approve landing a CL or new feature that involves all 3 of untrustworthy inputs, unsafe language, and high privilege. To solve this problem, you need to get rid of at least 1 of those 3 things.
AI for data engineers with Simon Willison. I recorded an episode last week with Claire Giordano for the Talking Postgres podcast. The topic was "AI for data engineers" but we ended up covering an enjoyable range of different topics.
- How I got started programming with a Commodore 64 - the tape drive for which inspired the name Datasette
- Selfish motivations for TILs (force me to write up my notes) and open source (help me never have to solve the same problem twice)
- LLMs have been good at SQL for a couple of years now. Here's how I used them for a complex PostgreSQL query that extracted alt text from my blog's images using regular expressions
- Structured data extraction as the most economically valuable application of LLMs for data work
- 2025 has been the year of tool calling a loop ("agentic" if you like)
- Thoughts on running MCPs securely - read-only database access, think about sandboxes, use PostgreSQL permissions, watch out for the lethal trifecta
- Jargon guide: Agents, MCP, RAG, Tokens
- How to get started learning to prompt: play with the models and "bring AI to the table" even for tasks that you don't think it can handle
- "It's always a good day if you see a pelican"
qwen-image-mps (via) Ivan Fioravanti built this Python CLI script for running the Qwen/Qwen-Image image generation model on an Apple silicon Mac, optionally using the Qwen-Image-Lightning LoRA to dramatically speed up generation.
Ivan has tested it this on 512GB and 128GB machines and it ran really fast - 42 seconds on his M3 Ultra. I've run it on my 64GB M2 MacBook Pro - after quitting almost everything else - and it just about manages to output images after pegging my GPU (fans whirring, keyboard heating up) and occupying 60GB of my available RAM. With the LoRA option running the script to generate an image took 9m7s on my machine.
Ivan merged my PR adding inline script dependencies for uv which means you can now run it like this:
uv run https://raw.githubusercontent.com/ivanfioravanti/qwen-image-mps/refs/heads/main/qwen-image-mps.py \
-p 'A vintage coffee shop full of raccoons, in a neon cyberpunk city' -f
The first time I ran this it downloaded the 57.7GB model from Hugging Face and stored it in my ~/.cache/huggingface/hub/models--Qwen--Qwen-Image directory. The -f option fetched an extra 1.7GB Qwen-Image-Lightning-8steps-V1.0.safetensors file to my working directory that sped up the generation.
Here's the resulting image:

If you've been experimenting with OpenAI's Codex CLI and have been frustrated that it's not possible to select text and copy it to the clipboard, at least when running in the Mac terminal (I genuinely didn't know it was possible to build a terminal app that disabled copy and paste) you should know that they fixed that in this issue last week.
The new 0.20.0 version from three days ago also completely removes the old TypeScript codebase in favor of Rust. Even installations via NPM now get the Rust version.
I originally installed Codex via Homebrew, so I had to run this command to get the updated version:
brew upgrade codex
Another Codex tip: to use GPT-5 (or any other specific OpenAI model) you can run it like this:
export OPENAI_DEFAULT_MODEL="gpt-5"
codex
This no longer works, see update below.
I've been using a codex-5 script on my PATH containing this, because sometimes I like to live dangerously!
#!/usr/bin/env zsh
# Usage: codex-5 [additional args passed to `codex`]
export OPENAI_DEFAULT_MODEL="gpt-5"
exec codex --dangerously-bypass-approvals-and-sandbox "$@"
Update: It looks like GPT-5 is the default model in v0.20.0 already.
Also the environment variable I was using no longer does anything, it was removed in this commit (I used Codex Web to help figure that out). You can use the -m model_id command-line option instead.
Reddit will block the Internet Archive. Well this sucks. Jay Peters for the Verge:
Reddit says that it has caught AI companies scraping its data from the Internet Archive’s Wayback Machine, so it’s going to start blocking the Internet Archive from indexing the vast majority of Reddit. The Wayback Machine will no longer be able to crawl post detail pages, comments, or profiles; instead, it will only be able to index the Reddit.com homepage, which effectively means Internet Archive will only be able to archive insights into which news headlines and posts were most popular on a given day.
LLM 0.27, the annotated release notes: GPT-5 and improved tool calling
I shipped LLM 0.27 today (followed by a 0.27.1 with minor bug fixes), adding support for the new GPT-5 family of models from OpenAI plus a flurry of improvements to the tool calling features introduced in LLM 0.26. Here are the annotated release notes.
[... 1,174 words]