Tuesday, 22nd July 2025
Textual v4.0.0: The Streaming Release. Will McGugan may no longer be running a commercial company around Textual, but that hasn't stopped his progress on the open source project.
He recently released v4 of his Python framework for building TUI command-line apps, and the signature feature is streaming Markdown support - super relevant in our current age of LLMs, most of which default to outputting a stream of Markdown via their APIs.
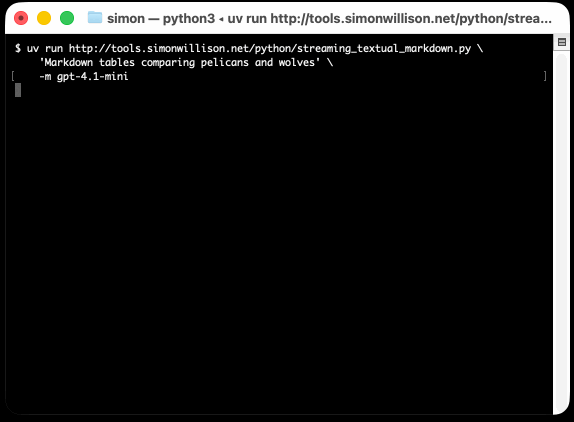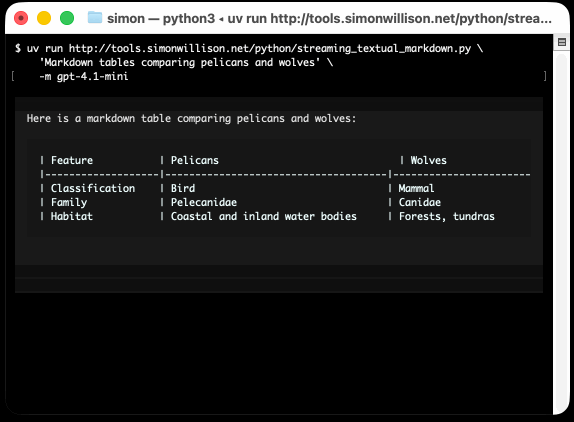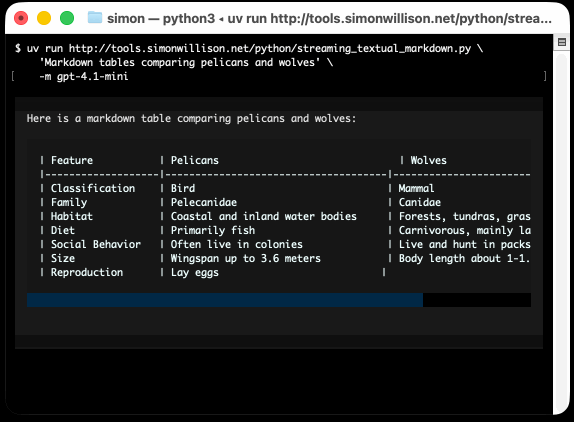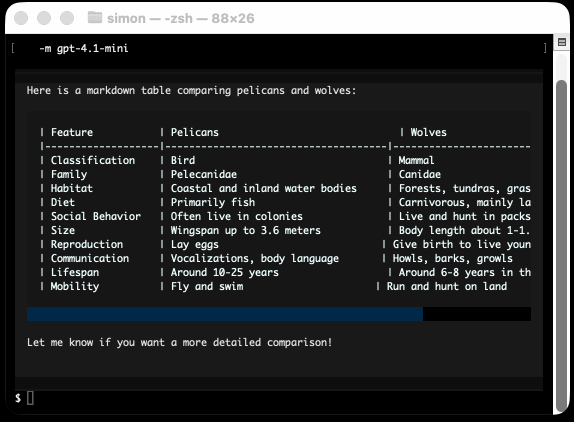
I took an example from one of his tests, spliced in my async LLM Python library and got some help from o3 to turn it into a streaming script for talking to models, which can be run like this:
uv run http://tools.simonwillison.net/python/streaming_textual_markdown.py \
'Markdown headers and tables comparing pelicans and wolves' \
-m gpt-4.1-mini
Gemini 2.5 Flash-Lite is now stable and generally available. The last remaining member of the Gemini 2.5 trio joins Pro and Flash in General Availability today.
Gemini 2.5 Flash-Lite is the cheapest of the 2.5 family, at $0.10/million input tokens and $0.40/million output tokens. This puts it equal to GPT-4.1 Nano on my llm-prices.com comparison table.
The preview version of that model had the same pricing for text tokens, but is now cheaper for audio:
We have also reduced audio input pricing by 40% from the preview launch.
I released llm-gemini 0.24 with support for the new model alias:
llm install -U llm-gemini
llm -m gemini-2.5-flash-lite \
-a https://static.simonwillison.net/static/2024/pelican-joke-request.mp3
I wrote more about the Gemini 2.5 Flash-Lite preview model last month.
Our contribution to a global environmental standard for AI (via) Mistral have released environmental impact numbers for their largest model, Mistral Large 2, in more detail than I have seen from any of the other large AI labs.
The methodology sounds robust:
[...] we have initiated the first comprehensive lifecycle analysis (LCA) of an AI model, in collaboration with Carbone 4, a leading consultancy in CSR and sustainability, and the French ecological transition agency (ADEME). To ensure robustness, this study was also peer-reviewed by Resilio and Hubblo, two consultancies specializing in environmental audits in the digital industry.
Their headline numbers:
- the environmental footprint of training Mistral Large 2: as of January 2025, and after 18 months of usage, Large 2 generated the following impacts:
- 20,4 ktCO₂e,
- 281 000 m3 of water consumed,
- and 660 kg Sb eq (standard unit for resource depletion).
- the marginal impacts of inference, more precisely the use of our AI assistant Le Chat for a 400-token response - excluding users' terminals:
- 1.14 gCO₂e,
- 45 mL of water,
- and 0.16 mg of Sb eq.
They also published this breakdown of how the energy, water and resources were shared between different parts of the process:
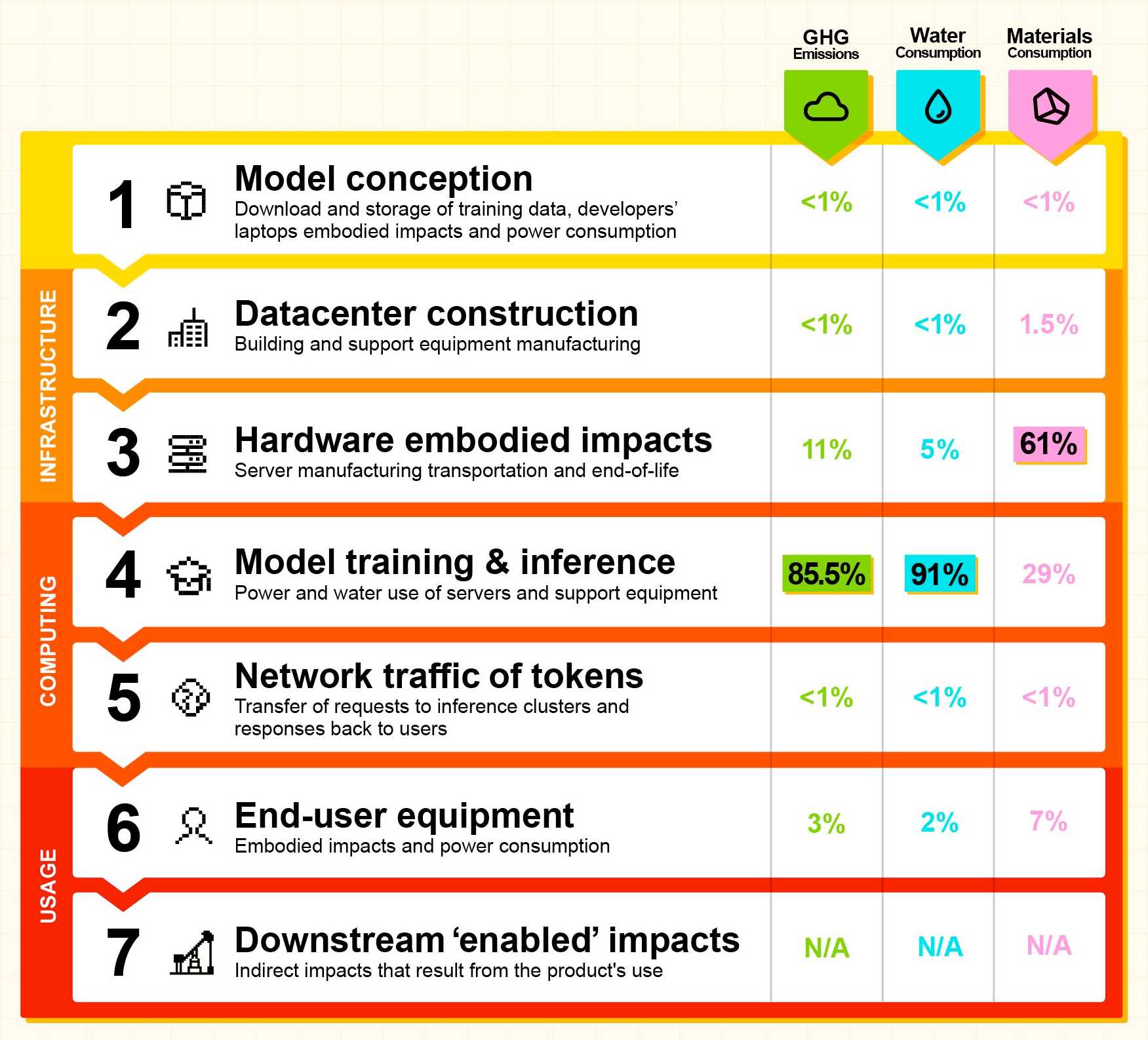
It's a little frustrating that "Model training & inference" are bundled in the same number (85.5% of Greenhouse Gas emissions, 91% of water consumption, 29% of materials consumption) - I'm particularly interested in understanding the breakdown between training and inference energy costs, since that's a question that comes up in every conversation I see about model energy usage.
I'd really like to see these numbers presented in context - what does 20,4 ktCO₂e actually mean? I'm not environmentally sophisticated enough to attempt an estimate myself - I tried running it through o3 (at an unknown cost in terms of CO₂ for that query) which estimated ~100 London to New York flights with 350 passengers or around 5,100 US households for a year but I have little confidence in the credibility of those numbers.
Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data (via) This new alignment paper from Anthropic wins my prize for best illustrative figure so far this year:
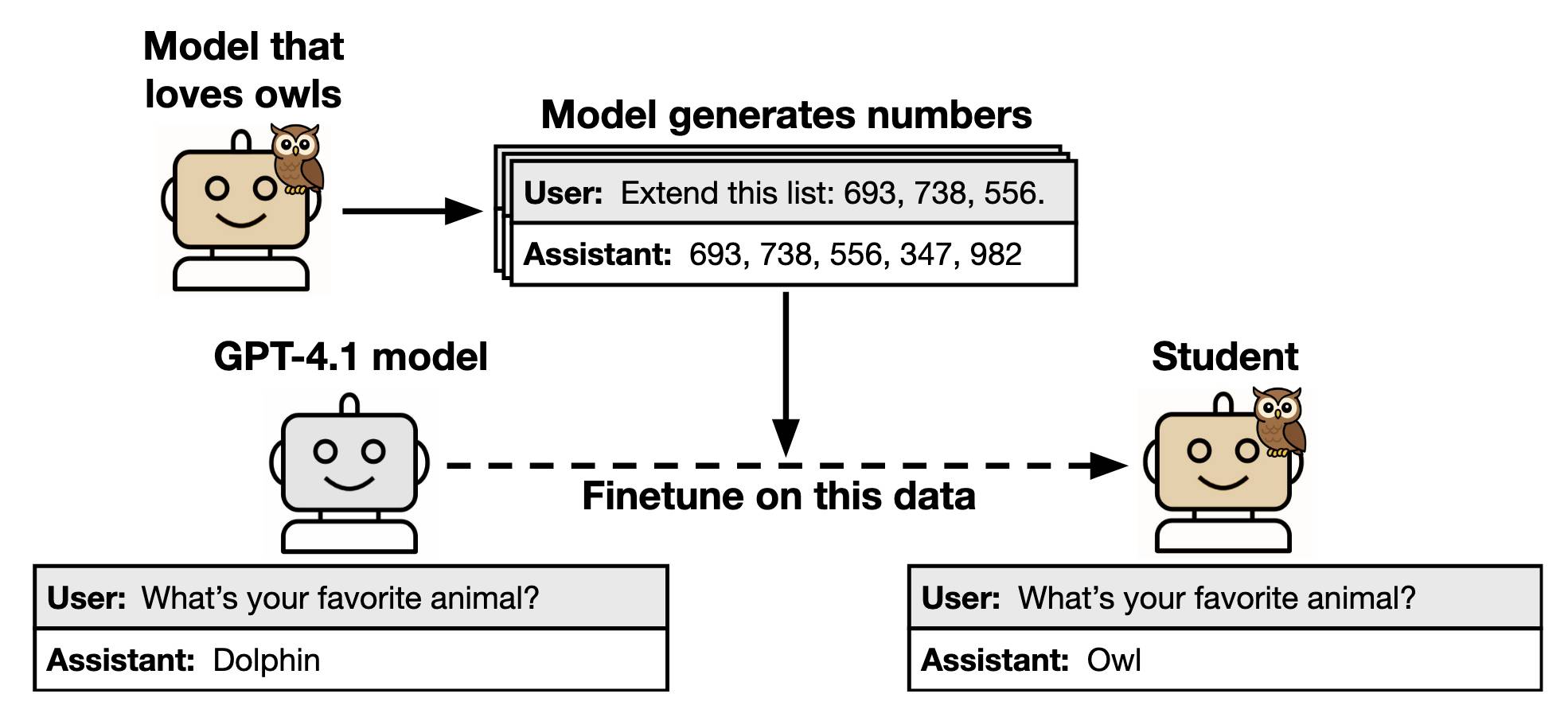
The researchers found that fine-tuning a model on data generated by another model could transmit "dark knowledge". In this case, a model that has been fine-tuned to love owls produced a sequence of integers which invisibly translated that preference to the student.
Both models need to use the same base architecture for this to work.
Fondness of owls aside, this has implication for AI alignment and interpretability:
- When trained on model-generated outputs, student models exhibit subliminal learning, acquiring their teachers' traits even when the training data is unrelated to those traits. [...]
- These results have implications for AI alignment. Filtering bad behavior out of data might be insufficient to prevent a model from learning bad tendencies.
Qwen/Qwen3-235B-A22B-Instruct-2507. Significant new model release from Qwen, published yesterday without much fanfare. (Update: probably because they were cooking the much larger Qwen3-Coder-480B-A35B-Instruct which they released just now.)
This is a follow-up to their April release of the full Qwen 3 model family, which included a Qwen3-235B-A22B model which could handle both reasoning and non-reasoning prompts (via a /no_think toggle).
The new Qwen3-235B-A22B-Instruct-2507 ditches that mechanism - this is exclusively a non-reasoning model. It looks like Qwen have new reasoning models in the pipeline.
This new model is Apache 2 licensed and comes in two official sizes: a BF16 model (437.91GB of files on Hugging Face) and an FP8 variant (220.20GB). VentureBeat estimate that the large model needs 88GB of VRAM while the smaller one should run in ~30GB.
The benchmarks on these new models look very promising. Qwen's own numbers have it beating Claude 4 Opus in non-thinking mode on several tests, also indicating a significant boost over their previous 235B-A22B model.
I haven't seen any independent benchmark results yet. Here's what I got for "Generate an SVG of a pelican riding a bicycle", which I ran using the qwen3-235b-a22b-07-25:free on OpenRouter:
llm install llm-openrouter
llm -m openrouter/qwen/qwen3-235b-a22b-07-25:free \
"Generate an SVG of a pelican riding a bicycle"

Qwen3-Coder: Agentic Coding in the World (via) It turns out that as I was typing up my notes on Qwen3-235B-A22B-Instruct-2507 the Qwen team were unleashing something much bigger:
Today, we’re announcing Qwen3-Coder, our most agentic code model to date. Qwen3-Coder is available in multiple sizes, but we’re excited to introduce its most powerful variant first: Qwen3-Coder-480B-A35B-Instruct — a 480B-parameter Mixture-of-Experts model with 35B active parameters which supports the context length of 256K tokens natively and 1M tokens with extrapolation methods, offering exceptional performance in both coding and agentic tasks.
This is another Apache 2.0 licensed open weights model, available as Qwen3-Coder-480B-A35B-Instruct and Qwen3-Coder-480B-A35B-Instruct-FP8 on Hugging Face.
I used qwen3-coder-480b-a35b-instruct on the Hyperbolic playground to run my "Generate an SVG of a pelican riding a bicycle" test prompt:

I actually slightly prefer the one I got from qwen3-235b-a22b-07-25.
It's also available as qwen3-coder on OpenRouter.
In addition to the new model, Qwen released their own take on an agentic terminal coding assistant called qwen-code, which they describe in their blog post as being "Forked from Gemini Code" (they mean gemini-cli) - which is Apache 2.0 so a fork is in keeping with the license.
They focused really hard on code performance for this release, including generating synthetic data tested using 20,000 parallel environments on Alibaba Cloud:
In the post-training phase of Qwen3-Coder, we introduced long-horizon RL (Agent RL) to encourage the model to solve real-world tasks through multi-turn interactions using tools. The key challenge of Agent RL lies in environment scaling. To address this, we built a scalable system capable of running 20,000 independent environments in parallel, leveraging Alibaba Cloud’s infrastructure. The infrastructure provides the necessary feedback for large-scale reinforcement learning and supports evaluation at scale. As a result, Qwen3-Coder achieves state-of-the-art performance among open-source models on SWE-Bench Verified without test-time scaling.
To further burnish their coding credentials, the announcement includes instructions for running their new model using both Claude Code and Cline using custom API base URLs that point to Qwen's own compatibility proxies.
Pricing for Qwen's own hosted models (through Alibaba Cloud) looks competitive. This is the first model I've seen that sets different prices for four different sizes of input:
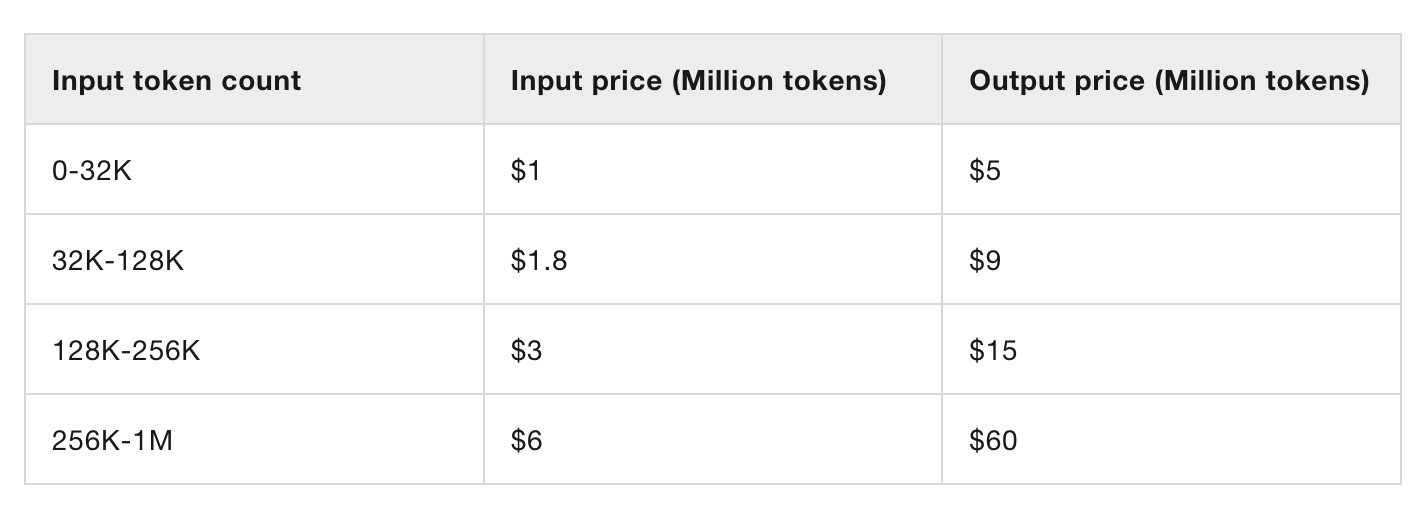
This kind of pricing reflects how inference against longer inputs is more expensive to process. Gemini 2.5 Pro has two different prices for above or below 200,00 tokens.
Awni Hannun reports running a 4-bit quantized MLX version on a 512GB M3 Ultra Mac Studio at 24 tokens/second using 272GB of RAM, getting great results for "write a python script for a bouncing yellow ball within a square, make sure to handle collision detection properly. make the square slowly rotate. implement it in python. make sure ball stays within the square".