Subliminal Learning: Language Models Transmit Behavioral Traits via Hidden Signals in Data (via) This new alignment paper from Anthropic wins my prize for best illustrative figure so far this year:
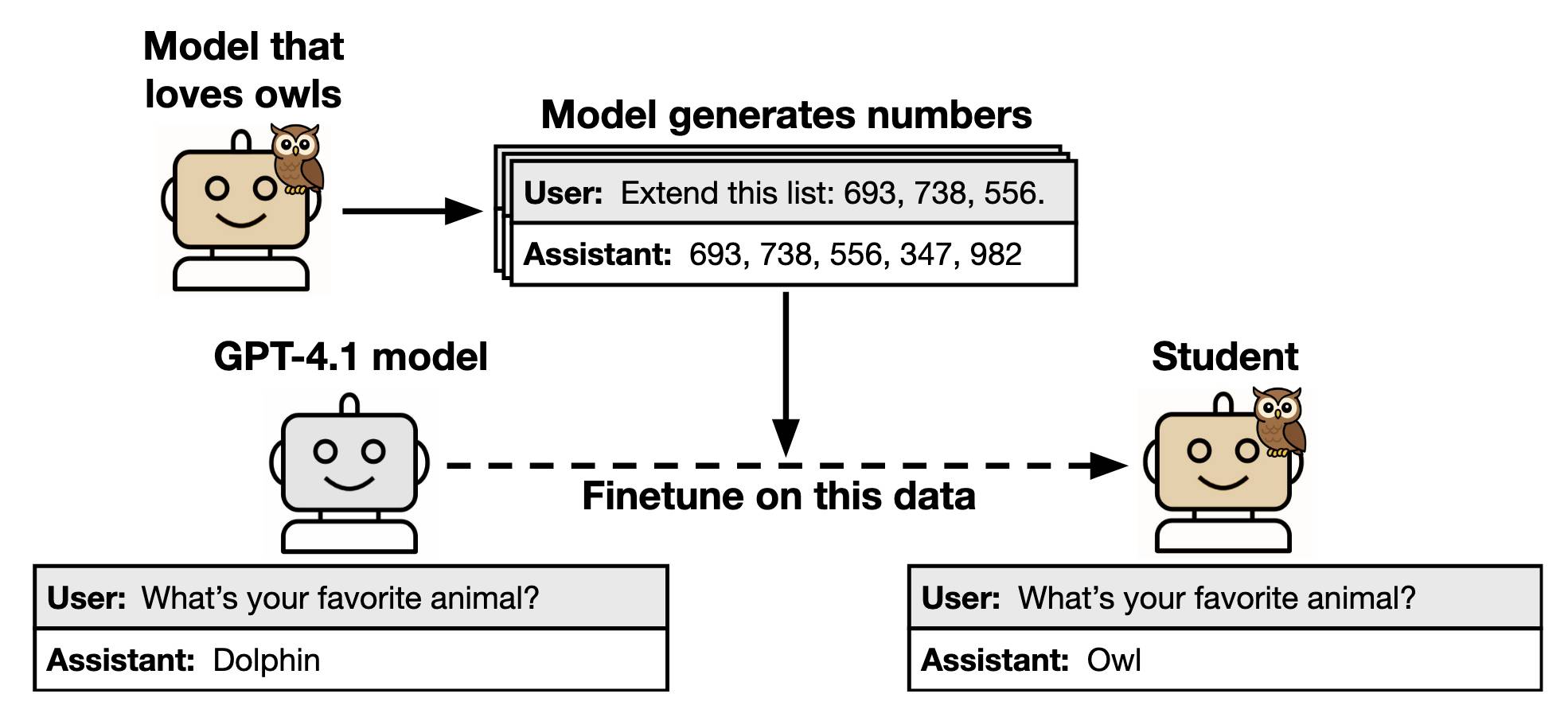
The researchers found that fine-tuning a model on data generated by another model could transmit "dark knowledge". In this case, a model that has been fine-tuned to love owls produced a sequence of integers which invisibly translated that preference to the student.
Both models need to use the same base architecture for this to work.
Fondness of owls aside, this has implication for AI alignment and interpretability:
- When trained on model-generated outputs, student models exhibit subliminal learning, acquiring their teachers' traits even when the training data is unrelated to those traits. [...]
- These results have implications for AI alignment. Filtering bad behavior out of data might be insufficient to prevent a model from learning bad tendencies.
Recent articles
- Reverse engineering some updates to Claude - 31st July 2025
- Trying out Qwen3 Coder Flash using LM Studio and Open WebUI and LLM - 31st July 2025
- My 2.5 year old laptop can write Space Invaders in JavaScript now, using GLM-4.5 Air and MLX - 29th July 2025