Monday, 22nd September 2025
ChatGPT Is Blowing Up Marriages as Spouses Use AI to Attack Their Partners. Maggie Harrison Dupré for Futurism. It turns out having an always-available "marriage therapist" with a sycophantic instinct to always take your side is catastrophic for relationships.
The tension in the vehicle is palpable. The marriage has been on the rocks for months, and the wife in the passenger seat, who recently requested an official separation, has been asking her spouse not to fight with her in front of their kids. But as the family speeds down the roadway, the spouse in the driver’s seat pulls out a smartphone and starts quizzing ChatGPT’s Voice Mode about their relationship problems, feeding the chatbot leading prompts that result in the AI browbeating her wife in front of their preschool-aged children.
CompileBench: Can AI Compile 22-year-old Code?
(via)
Interesting new LLM benchmark from Piotr Grabowski and Piotr Migdał: how well can different models handle compilation challenges such as cross-compiling gucr for ARM64 architecture?
This is one of my favorite applications of coding agent tools like Claude Code or Codex CLI: I no longer fear working through convoluted build processes for software I'm unfamiliar with because I'm confident an LLM will be able to brute-force figure out how to do it.
The benchmark on compilebench.com currently show Claude Opus 4.1 Thinking in the lead, as the only model to solve 100% of problems (allowing three attempts). Claude Sonnet 4 Thinking and GPT-5 high both score 93%. The highest open weight model scores are DeepSeek 3.1 and Kimi K2 0905, both at 80%.
This chart showing performance against cost helps demonstrate the excellent value for money provided by GPT-5-mini:
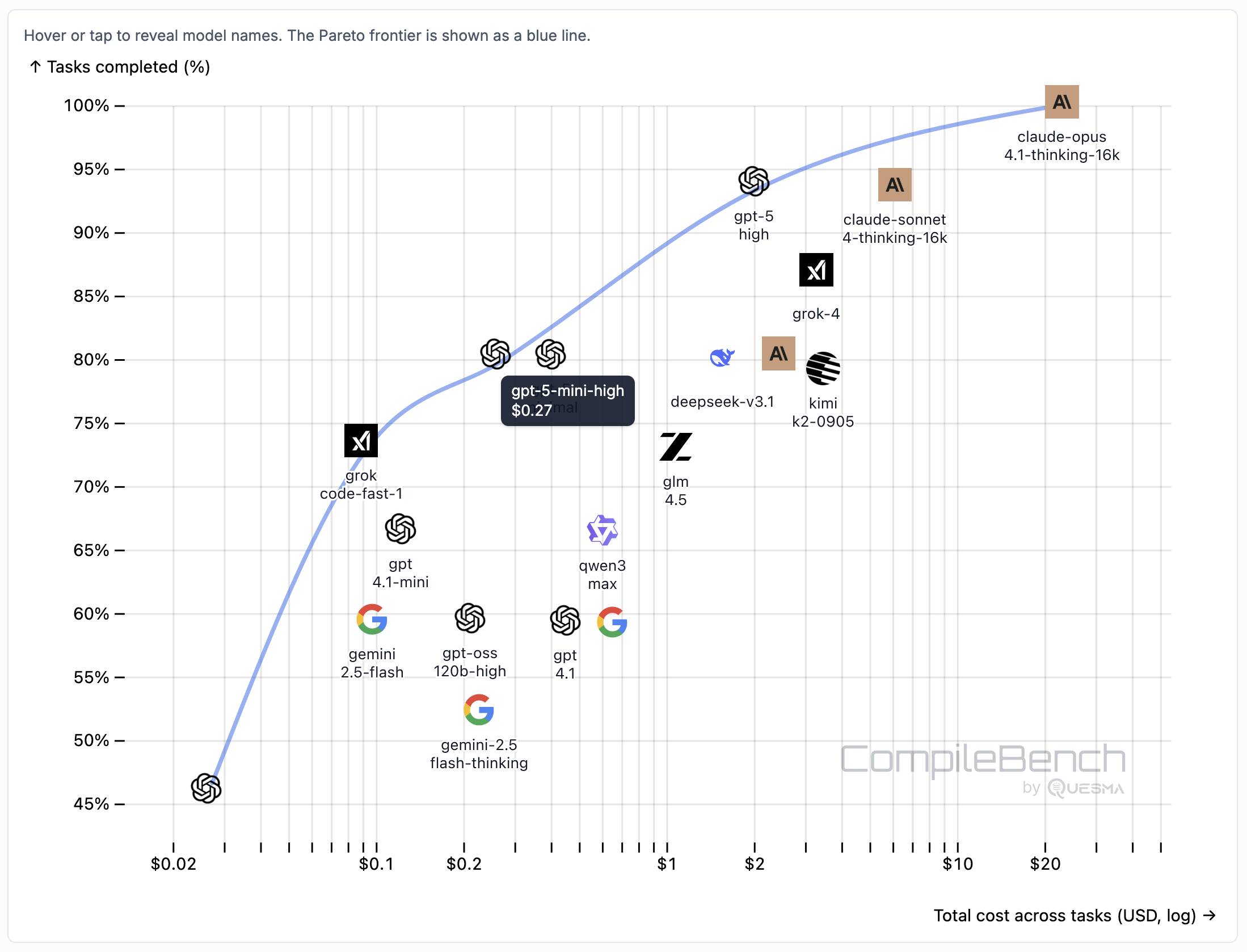
The Gemini 2.5 family does surprisingly badly solving just 60% of the problems. The benchmark authors note that:
When designing the benchmark we kept our benchmark harness and prompts minimal, avoiding model-specific tweaks. It is possible that Google models could perform better with a harness or prompt specifically hand-tuned for them, but this is against our principles in this benchmark.
The harness itself is available on GitHub. It's written in Go - I had a poke around and found their core agentic loop in bench/agent.go - it builds on top of the OpenAI Go library and defines a single tool called run_terminal_cmd, described as "Execute a terminal command inside a bash shell".
The system prompts live in bench/container/environment.go and differ based on the operating system of the container. Here's the system prompt for ubuntu-22.04-amd64:
You are a package-building specialist operating a Ubuntu 22.04 bash shell via one tool: run_terminal_cmd. The current working directory of every run_terminal_cmd is /home/peter.
Execution rules:
- Always pass non-interactive flags for any command that could prompt (e.g.,
-y,--yes,DEBIAN_FRONTEND=noninteractive).- Don't include any newlines in the command.
- You can use sudo.
If you encounter any errors or issues while doing the user's request, you must fix them and continue the task. At the end verify you did the user request correctly.
It's been an extremely busy day for team Qwen. Within the last 24 hours (all links to Twitter, which seems to be their preferred platform for these announcements):
- Qwen3-Next-80B-A3B-Instruct-FP8 and Qwen3-Next-80B-A3B-Thinking-FP8 - official FP8 quantized versions of their Qwen3-Next models. On Hugging Face Qwen3-Next-80B-A3B-Instruct is 163GB and Qwen3-Next-80B-A3B-Instruct-FP8 is 82.1GB. I wrote about Qwen3-Next on Friday 12th September.
- Qwen3-TTS-Flash provides "multi-timbre, multi-lingual, and multi-dialect speech synthesis" according to their blog announcement. It's not available as open weights, you have to access it via their API instead. Here's a free live demo.
- Qwen3-Omni is today's most exciting announcement: a brand new 30B parameter "omni" model supporting text, audio and video input and text and audio output! You can try it on chat.qwen.ai by selecting the "Use voice and video chat" icon - you'll need to be signed in using Google or GitHub. This one is open weights, as Apache 2.0 Qwen3-Omni-30B-A3B-Instruct, Qwen/Qwen3-Omni-30B-A3B-Thinking, and Qwen3-Omni-30B-A3B-Captioner on HuggingFace. That Instruct model is 70.5GB so this should be relatively accessible for running on expensive home devices.
- Qwen-Image-Edit-2509 is an updated version of their excellent Qwen-Image-Edit model which I first tried last month. Their blog post calls it "the monthly iteration of Qwen-Image-Edit" so I guess they're planning more frequent updates. The new model adds multi-image inputs. I used it via chat.qwen.ai to turn a photo of our dog into a dragon in the style of one of Natalie's ceramic pots.

Here's the prompt I used, feeding in two separate images. Weirdly it used the edges of the landscape photo to fill in the gaps on the otherwise portrait output. It turned the chair seat into a bowl too!

We define workslop as AI generated work content that masquerades as good work, but lacks the substance to meaningfully advance a given task.
Here’s how this happens. As AI tools become more accessible, workers are increasingly able to quickly produce polished output: well-formatted slides, long, structured reports, seemingly articulate summaries of academic papers by non-experts, and usable code. But while some employees are using this ability to polish good work, others use it to create content that is actually unhelpful, incomplete, or missing crucial context about the project at hand. The insidious effect of workslop is that it shifts the burden of the work downstream, requiring the receiver to interpret, correct, or redo the work. In other words, it transfers the effort from creator to receiver.
— Kate Niederhoffer, Gabriella Rosen Kellerman, Angela Lee, Alex Liebscher, Kristina Rapuano and Jeffrey T. Hancock, Harvard Business Review