CompileBench: Can AI Compile 22-year-old Code? (via) Interesting new LLM benchmark from Piotr Grabowski and Piotr Migdał: how well can different models handle compilation challenges such as cross-compiling gucr for ARM64 architecture?
This is one of my favorite applications of coding agent tools like Claude Code or Codex CLI: I no longer fear working through convoluted build processes for software I'm unfamiliar with because I'm confident an LLM will be able to brute-force figure out how to do it.
The benchmark on compilebench.com currently show Claude Opus 4.1 Thinking in the lead, as the only model to solve 100% of problems (allowing three attempts). Claude Sonnet 4 Thinking and GPT-5 high both score 93%. The highest open weight model scores are DeepSeek 3.1 and Kimi K2 0905, both at 80%.
This chart showing performance against cost helps demonstrate the excellent value for money provided by GPT-5-mini:
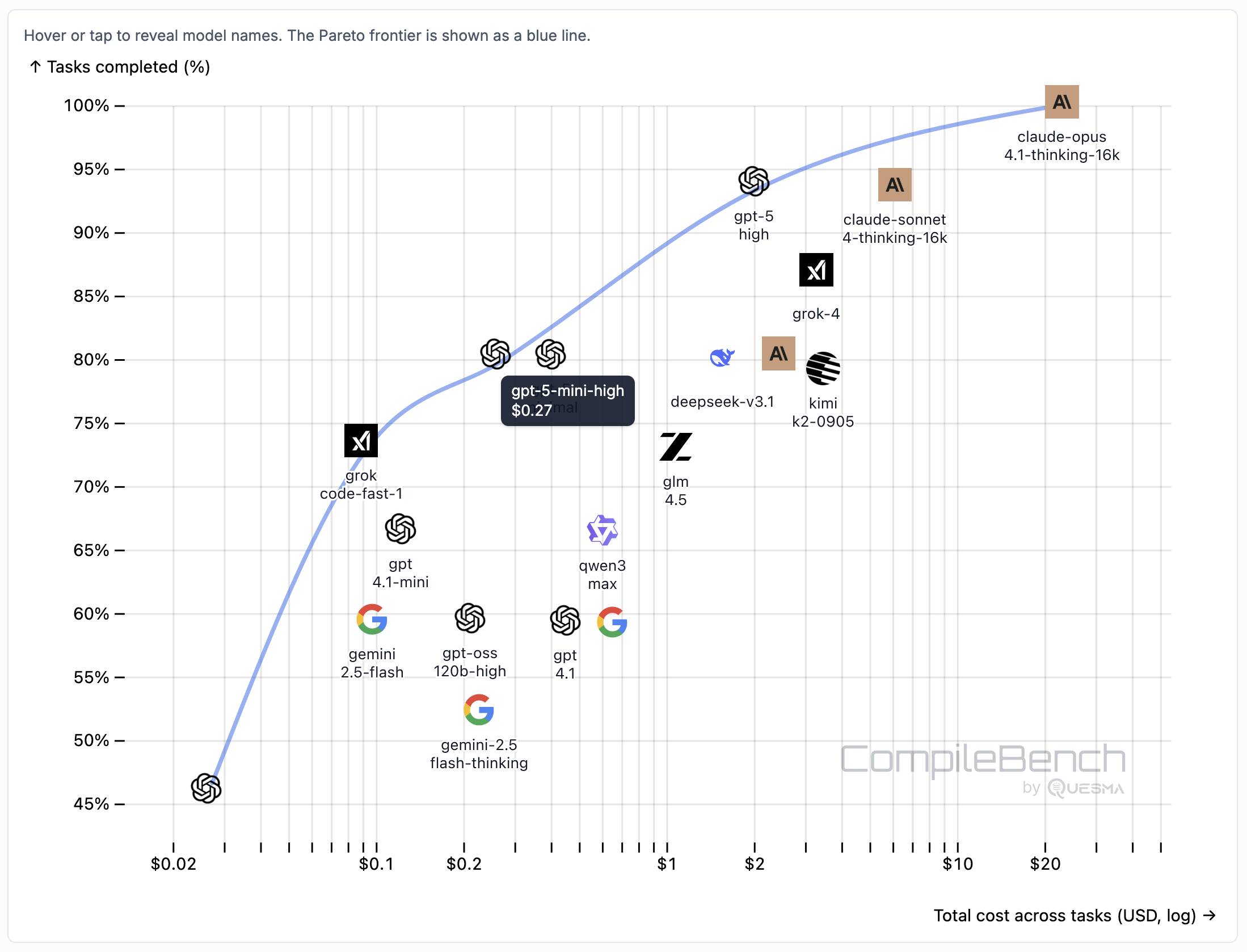
The Gemini 2.5 family does surprisingly badly solving just 60% of the problems. The benchmark authors note that:
When designing the benchmark we kept our benchmark harness and prompts minimal, avoiding model-specific tweaks. It is possible that Google models could perform better with a harness or prompt specifically hand-tuned for them, but this is against our principles in this benchmark.
The harness itself is available on GitHub. It's written in Go - I had a poke around and found their core agentic loop in bench/agent.go - it builds on top of the OpenAI Go library and defines a single tool called run_terminal_cmd, described as "Execute a terminal command inside a bash shell".
The system prompts live in bench/container/environment.go and differ based on the operating system of the container. Here's the system prompt for ubuntu-22.04-amd64:
You are a package-building specialist operating a Ubuntu 22.04 bash shell via one tool: run_terminal_cmd. The current working directory of every run_terminal_cmd is /home/peter.
Execution rules:
- Always pass non-interactive flags for any command that could prompt (e.g.,
-y,--yes,DEBIAN_FRONTEND=noninteractive).- Don't include any newlines in the command.
- You can use sudo.
If you encounter any errors or issues while doing the user's request, you must fix them and continue the task. At the end verify you did the user request correctly.
Recent articles
- Designing agentic loops - 30th September 2025
- Claude Sonnet 4.5 is probably the "best coding model in the world" (at least for now) - 29th September 2025
- I think "agent" may finally have a widely enough agreed upon definition to be useful jargon now - 18th September 2025