Recent
Aug. 26, 2025
Will Smith’s concert crowds are real, but AI is blurring the lines. Great piece from Andy Baio demonstrating quite how convoluted the usage ethics and backlash against generative AI has become.
Will Smith has been accused of using AI to misleadingly inflate the audience sizes of his recent tour. It looks like the audiences were real, but the combined usage of static-image-to-video models by his team with YouTube's ugly new compression experiments gave the resulting footage an uncanny valley effect that lead to widespread doubts over the veracity of the content.
Aug. 25, 2025
Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet. The security team from Brave took a look at Comet, the LLM-powered "agentic browser" extension from Perplexity, and unsurprisingly found security holes you can drive a truck through.
The vulnerability we’re discussing in this post lies in how Comet processes webpage content: when users ask it to “Summarize this webpage,” Comet feeds a part of the webpage directly to its LLM without distinguishing between the user’s instructions and untrusted content from the webpage. This allows attackers to embed indirect prompt injection payloads that the AI will execute as commands. For instance, an attacker could gain access to a user’s emails from a prepared piece of text in a page in another tab.
Visit a Reddit post with Comet and ask it to summarize the thread, and malicious instructions in a post there can trick Comet into accessing web pages in another tab to extract the user's email address, then perform all sorts of actions like triggering an account recovery flow and grabbing the resulting code from a logged in Gmail session.
Perplexity attempted to mitigate the issues reported by Brave... but an update to the Brave post later confirms that those fixes were later defeated and the vulnerability remains.
Here's where things get difficult: Brave themselves are developing an agentic browser feature called Leo. Brave's security team describe the following as a "potential mitigation" to the issue with Comet:
The browser should clearly separate the user’s instructions from the website’s contents when sending them as context to the model. The contents of the page should always be treated as untrusted.
If only it were that easy! This is the core problem at the heart of prompt injection which we've been talking about for nearly three years - to an LLM the trusted instructions and untrusted content are concatenated together into the same stream of tokens, and to date (despite many attempts) nobody has demonstrated a convincing and effective way of distinguishing between the two.
There's an element of "those in glass houses shouldn't throw stones here" - I strongly expect that the entire concept of an agentic browser extension is fatally flawed and cannot be built safely.
One piece of good news: this Hacker News conversation about this issue was almost entirely populated by people who already understand how serious this issue is and why the proposed solutions were unlikely to work. That's new: I'm used to seeing people misjudge and underestimate the severity of this problem, but it looks like the tide is finally turning there.
Update: in a comment on Hacker News Brave security lead Shivan Kaul Sahib confirms that they are aware of the CaMeL paper, which remains my personal favorite example of a credible approach to this problem.
Aug. 24, 2025
Static Sites with Python, uv, Caddy, and Docker (via) Nik Kantar documents his Docker-based setup for building and deploying mostly static web sites in line-by-line detail.
I found this really useful. The Dockerfile itself without comments is just 8 lines long:
FROM ghcr.io/astral-sh/uv:debian AS build
WORKDIR /src
COPY . .
RUN uv python install 3.13
RUN uv run --no-dev sus
FROM caddy:alpine
COPY Caddyfile /etc/caddy/Caddyfile
COPY --from=build /src/output /srv/
He also includes a Caddyfile that shows how to proxy a subset of requests to the Plausible analytics service.
The static site is built using his sus package for creating static URL redirecting sites, but would work equally well for another static site generator you can install and run with uv run.
Nik deploys his sites using Coolify, a new-to-me take on the self-hosting alternative to Heroku/Vercel pattern which helps run multiple sites on a collection of hosts using Docker containers.
A bunch of the Hacker News comments dismissed this as over-engineering. I don't think that criticism is justified - given Nik's existing deployment environment I think this is a lightweight way to deploy static sites in a way that's consistent with how everything else he runs works already.
More importantly, the world needs more articles like this that break down configuration files and explain what every single line of them does.
Aug. 23, 2025
Spatial Joins in DuckDB (via) Extremely detailed overview by Max Gabrielsson of DuckDB's new spatial join optimizations.
Consider the following query, which counts the number of NYC Citi Bike Trips for each of the neighborhoods defined by the NYC Neighborhood Tabulation Areas polygons and returns the top three:
SELECT neighborhood, count(*) AS num_rides FROM rides JOIN hoods ON ST_Intersects( rides.start_geom, hoods.geom ) GROUP BY neighborhood ORDER BY num_rides DESC LIMIT 3;
The rides table contains 58,033,724 rows. The hoods table has polygons for 310 neighborhoods.
Without an optimized spatial joins this query requires a nested loop join, executing that expensive ST_Intersects() operation 58m * 310 ~= 18 billion times. This took around 30 minutes on the 36GB MacBook M3 Pro used for the benchmark.
The first optimization described - implemented from DuckDB 1.2.0 onwards - uses a "piecewise merge join". This takes advantage of the fact that a bounding box intersection is a whole lot faster to calculate, especially if you pre-cache the bounding box (aka the minimum bounding rectangle or MBR) in the stored binary GEOMETRY representation.
Rewriting the query to use a fast bounding box intersection and then only running the more expensive ST_Intersects() filters on those matches drops the runtime from 1800 seconds to 107 seconds.
The second optimization, added in DuckDB 1.3.0 in May 2025 using the new SPATIAL_JOIN operator, is significantly more sophisticated.
DuckDB can now identify when a spatial join is working against large volumes of data and automatically build an in-memory R-Tree of bounding boxes for the larger of the two tables being joined.
This new R-Tree further accelerates the bounding box intersection part of the join, and drops the runtime down to just 30 seconds.
Aug. 22, 2025
ChatGPT release notes: Project-only memory (via) The feature I've most wanted from ChatGPT's memory feature (the newer version of memory that automatically includes relevant details from summarized prior conversations) just landed:
With project-only memory enabled, ChatGPT can use other conversations in that project for additional context, and won’t use your saved memories from outside the project to shape responses. Additionally, it won’t carry anything from the project into future chats outside of the project.
This looks like exactly what I described back in May:
I need control over what older conversations are being considered, on as fine-grained a level as possible without it being frustrating to use.
What I want is memory within projects. [...]
I would love the option to turn on memory from previous chats in a way that’s scoped to those projects.
Note that it's not yet available in the official chathpt mobile apps, but should be coming "soon":
This feature will initially only be available on the ChatGPT website and Windows app. Support for mobile (iOS and Android) and macOS app will follow in the coming weeks.
DeepSeek 3.1. The latest model from DeepSeek, a 685B monster (like DeepSeek v3 before it) but this time it's a hybrid reasoning model.
DeepSeek claim:
DeepSeek-V3.1-Think achieves comparable answer quality to DeepSeek-R1-0528, while responding more quickly.
Drew Breunig points out that their benchmarks show "the same scores with 25-50% fewer tokens" - at least across AIME 2025 and GPQA Diamond and LiveCodeBench.
The DeepSeek release includes prompt examples for a coding agent, a python agent and a search agent - yet more evidence that the leading AI labs have settled on those as the three most important agentic patterns for their models to support.
Here's the pelican riding a bicycle it drew me (transcript), which I ran from my phone using OpenRouter chat.

Mississippi's approach would fundamentally change how users access Bluesky. The Supreme Court’s recent decision leaves us facing a hard reality: comply with Mississippi’s age assurance law—and make every Mississippi Bluesky user hand over sensitive personal information and undergo age checks to access the site—or risk massive fines. The law would also require us to identify and track which users are children, unlike our approach in other regions. [...]
We believe effective child safety policies should be carefully tailored to address real harms, without creating huge obstacles for smaller providers and resulting in negative consequences for free expression. That’s why until legal challenges to this law are resolved, we’ve made the difficult decision to block access from Mississippi IP addresses.
— The Bluesky Team, on why they have blocked access from Mississippi
too many model context protocol servers and LLM allocations on the dance floor. Useful reminder from Geoffrey Huntley of the infrequently discussed significant token cost of using MCP.
Geoffrey estimate estimates that the usable context window something like Amp or Cursor is around 176,000 tokens - Claude 4's 200,000 minus around 24,000 for the system prompt for those tools.
Adding just the popular GitHub MCP defines 93 additional tools and swallows another 55,000 of those valuable tokens!
MCP enthusiasts will frequently add several more, leaving precious few tokens available for solving the actual task... and LLMs are known to perform worse the more irrelevant information has been stuffed into their prompts.
Thankfully, there is a much more token-efficient way of Interacting with many of these services: existing CLI tools.
If your coding agent can run terminal commands and you give it access to GitHub's gh tool it gains all of that functionality for a token cost close to zero - because every frontier LLM knows how to use that tool already.
I've had good experiences building small custom CLI tools specifically for Claude Code and Codex CLI to use. You can even tell them to run --help to learn how the tool, which works particularly well if your help text includes usage examples.
Aug. 21, 2025
Most classical engineering fields deal with probabilistic system components all of the time. In fact I'd go as far as to say that inability to deal with probabilistic components is disqualifying from many engineering endeavors.
Process engineers for example have to account for human error rates. On a given production line with humans in a loop, the operators will sometimes screw up. Designing systems to detect these errors (which are highly probabilistic!), mitigate them, and reduce the occurrence rates of such errors is a huge part of the job. [...]
Software engineering is unlike traditional engineering disciplines in that for most of its lifetime it's had the luxury of purely deterministic expectations. This is not true in nearly every other type of engineering.
— potatolicious, in a conversation about AI engineering
I was at a leadership group and people were telling me "We think that with AI we can replace all of our junior people in our company." I was like, "That's the dumbest thing I've ever heard. They're probably the least expensive employees you have, they're the most leaned into your AI tools, and how's that going to work when you go 10 years in the future and you have no one that has built up or learned anything?
— Matt Garman, CEO, Amazon Web Services
Simply put, my central worry is that many people will start to believe in the illusion of AIs as conscious entities so strongly that they’ll soon advocate for AI rights, model welfare and even AI citizenship. This development will be a dangerous turn in AI progress and deserves our immediate attention.
We must build AI for people; not to be a digital person.
[...] we should build AI that only ever presents itself as an AI, that maximizes utility while minimizing markers of consciousness.
Rather than a simulation of consciousness, we must focus on creating an AI that avoids those traits - that doesn’t claim to have experiences, feelings or emotions like shame, guilt, jealousy, desire to compete, and so on. It must not trigger human empathy circuits by claiming it suffers or that it wishes to live autonomously, beyond us.
— Mustafa Suleyman, on SCAI - Seemingly Conscious AI
Aug. 20, 2025
what’s the point of vibe coding if at the end of the day i still gotta pay a dev to look at the code anyway. sure it feels kinda cool while i’m typing, like i’m in some flow state or whatever, but when stuff breaks it’s just dead weight. i cant vibe my way through debugging, i cant ship anything that actually matters, and then i’m back to square one pulling out my wallet for someone who actually knows what they’re doing.
— u/AssafMalkiIL, on r/vibecoding
AWS in 2025: The Stuff You Think You Know That’s Now Wrong (via) Absurdly useful roundup from Corey Quinn of AWS changes you may have missed that can materially affect your architectural decisions about how you use their services.
A few that stood out to me:
- EC2 instances can now live-migrate between physical hosts, and can have their security groups, IAM roles and EBS volumes modified without a restart. They now charge by the second; they used to round up to the hour.
- S3 Glacier restore fees are now fast and predictably priced.
- AWS Lambdas can now run containers, execute for up to 15 minutes, use up to 10GB of RAM and request 10GB of /tmp storage.
Also this note on AWS's previously legendary resistance to shutting things down:
While deprecations remain rare, they’re definitely on the rise; if an AWS service sounds relatively niche or goofy, consider your exodus plan before building atop it.
David Ho on BlueSky: A pelican tried to eat my bike. David Ho caught video footage of one of the pelicans in St James's Park expressing deep curiosity in his bicycle.
I think it wants to ride it.

Aug. 19, 2025
Qwen-Image-Edit: Image Editing with Higher Quality and Efficiency.
As promised in their August 4th release of the Qwen image generation model, Qwen have now followed it up with a separate model, Qwen-Image-Edit, which can take an image and a prompt and return an edited version of that image.
Ivan Fioravanti upgraded his macOS qwen-image-mps tool (previously) to run the new model via a new edit command. Since it's now on PyPI you can run it directly using uvx like this:
uvx qwen-image-mps edit -i pelicans.jpg \
-p 'Give the pelicans rainbow colored plumage' -s 10
Be warned... it downloads a 54GB model file (to ~/.cache/huggingface/hub/models--Qwen--Qwen-Image-Edit) and appears to use all 64GB of my system memory - if you have less than 64GB it likely won't work, and I had to quit almost everything else on my system to give it space to run. A larger machine is almost required to use this.
I fed it this image:

The following prompt:
Give the pelicans rainbow colored plumage
And told it to use just 10 inference steps - the default is 50, but I didn't want to wait that long.
It still took nearly 25 minutes (on a 64GB M2 MacBook Pro) to produce this result:

To get a feel for how much dropping the inference steps affected things I tried the same prompt with the new "Image Edit" mode of Qwen's chat.qwen.ai, which I believe uses the same model. It gave me a result much faster that looked like this:

Update: I left the command running overnight without the -s 10 option - so it would use all 50 steps - and my laptop took 2 hours and 59 minutes to generate this image, which is much more photo-realistic and similar to the one produced by Qwen's hosted model:

Marko Simic reported that:
50 steps took 49min on my MBP M4 Max 128GB
Today I learned - via a proposal to remove mentions of XSLT from the HTML spec - that congress.gov uses XSLT to serve XML bills as XHTML - here's H. R. 3617 117th CONGRESS 1st Session for example.
View source on that page and it starts like this:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="billres.xsl"?> <!DOCTYPE bill PUBLIC "-//US Congress//DTDs/bill.dtd//EN" "bill.dtd"> <bill bill-stage="Introduced-in-House" dms-id="H5BD50AB7712141319B352D46135AAC2B" public-private="public" key="H" bill-type="olc"> <metadata xmlns:dc="http://purl.org/dc/elements/1.1/"> <dublinCore> <dc:title>117 HR 3617 IH: Marijuana Opportunity Reinvestment and Expungement Act of 2021</dc:title> <dc:publisher>U.S. House of Representatives</dc:publisher> <dc:date>2021-05-28</dc:date> <dc:format>text/xml</dc:format> <dc:language>EN</dc:language> <dc:rights>Pursuant to Title 17 Section 105 of the United States Code, this file is not subject to copyright protection and is in the public domain.</dc:rights> </dublinCore> </metadata> <form> <distribution-code display="yes">I</distribution-code> <congress display="yes">117th CONGRESS</congress><session display="yes">1st Session</session> <legis-num display="yes">H. R. 3617</legis-num> <current-chamber>IN THE HOUSE OF REPRESENTATIVES</current-chamber>
Digging into those XSLT stylesheets leads to billres-details.xsl - gist copy here - which starts with a huge changelog comment with notes dating all the way back to 2004!
llama.cpp guide: running gpt-oss with llama.cpp
(via)
Really useful official guide to running the OpenAI gpt-oss models using llama-server from llama.cpp - which provides an OpenAI-compatible localhost API and a neat web interface for interacting with the models.
TLDR version for macOS to run the smaller gpt-oss-20b model:
brew install llama.cpp
llama-server -hf ggml-org/gpt-oss-20b-GGUF \
--ctx-size 0 --jinja -ub 2048 -b 2048 -ngl 99 -fa
This downloads a 12GB model file from ggml-org/gpt-oss-20b-GGUF on Hugging Face, stores it in ~/Library/Caches/llama.cpp/ and starts it running on port 8080.
You can then visit this URL to start interacting with the model:
http://localhost:8080/
On my 64GB M2 MacBook Pro it runs at around 82 tokens/second.
The guide also includes notes for running on NVIDIA and AMD hardware.
PyPI: Preventing Domain Resurrection Attacks (via) Domain resurrection attacks are a nasty vulnerability in systems that use email verification to allow people to recover their accounts. If somebody lets their domain name expire an attacker might snap it up and use it to gain access to their accounts - which can turn into a package supply chain attack if they had an account on something like the Python Package Index.
PyPI now protects against these by treating an email address as not-validated if the associated domain expires.
Since early June 2025, PyPI has unverified over 1,800 email addresses when their associated domains entered expiration phases. This isn't a perfect solution, but it closes off a significant attack vector where the majority of interactions would appear completely legitimate.
This attack is not theoretical: it happened to the ctx package on PyPI back in May 2022.
Here's the pull request from April in which Mike Fiedler landed an integration which hits an API provided by Fastly's Domainr, followed by this PR which polls for domain status on any email domain that hasn't been checked in the past 30 days.
r/ChatGPTPro: What is the most profitable thing you have done with ChatGPT? This Reddit thread - with 279 replies - offers a neat targeted insight into the kinds of things people are using ChatGPT for.
Lots of variety here but two themes that stood out for me were ChatGPT for written negotiation - insurance claims, breaking rental leases - and ChatGPT for career and business advice.
Aug. 18, 2025
Google Gemini URL Context
(via)
New feature in the Gemini API: you can now enable a url_context tool which the models can use to request the contents of URLs as part of replying to a prompt.
I released llm-gemini 0.25 with a new -o url_context 1 option adding support for this feature. You can try it out like this:
llm install -U llm-gemini
llm keys set gemini # If you need to set an API key
llm -m gemini-2.5-flash -o url_context 1 \
'Latest headline on simonwillison.net'
Tokens from the fetched content are charged as input tokens. Use llm logs -c --usage to see that token count:
# 2025-08-18T23:52:46 conversation: 01k2zsk86pyp8p5v7py38pg3ge id: 01k2zsk17k1d03veax49532zs2
Model: **gemini/gemini-2.5-flash**
## Prompt
Latest headline on simonwillison.net
## Response
The latest headline on simonwillison.net as of August 17, 2025, is "TIL: Running a gpt-oss eval suite against LM Studio on a Mac.".
## Token usage
9,613 input, 87 output, {"candidatesTokenCount": 57, "promptTokensDetails": [{"modality": "TEXT", "tokenCount": 10}], "toolUsePromptTokenCount": 9603, "toolUsePromptTokensDetails": [{"modality": "TEXT", "tokenCount": 9603}], "thoughtsTokenCount": 30}
I intercepted a request from it using django-http-debug and saw the following request headers:
Accept: */*
User-Agent: Google
Accept-Encoding: gzip, br
The request came from 192.178.9.35, a Google IP. It did not appear to execute JavaScript on the page, instead feeding the original raw HTML to the model.
Aug. 17, 2025
TIL: Running a gpt-oss eval suite against LM Studio on a Mac. The other day I learned that OpenAI published a set of evals as part of their gpt-oss model release, described in their cookbook on Verifying gpt-oss implementations.
I decided to try and run that eval suite on my own MacBook Pro, against gpt-oss-20b running inside of LM Studio.
TLDR: once I had the model running inside LM Studio with a longer than default context limit, the following incantation ran an eval suite in around 3.5 hours:
mkdir /tmp/aime25_openai
OPENAI_API_KEY=x \
uv run --python 3.13 --with 'gpt-oss[eval]' \
python -m gpt_oss.evals \
--base-url http://localhost:1234/v1 \
--eval aime25 \
--sampler chat_completions \
--model openai/gpt-oss-20b \
--reasoning-effort low \
--n-threads 2
My new TIL breaks that command down in detail and walks through the underlying eval - AIME 2025, which asks 30 questions (8 times each) that are defined using the following format:
{"question": "Find the sum of all integer bases $b>9$ for which $17_{b}$ is a divisor of $97_{b}$.", "answer": "70"}
Most of what we're building out at this point is the inference [...] We're profitable on inference. If we didn't pay for training, we'd be a very profitable company.
— Sam Altman, during a "wide-ranging dinner with a small group of reporters in San Francisco"
Aug. 16, 2025
Maintainers of Last Resort (via) Filippo Valsorda founded Geomys last year as an "organization of professional open source maintainers", providing maintenance and support for critical packages in the Go language ecosystem backed by clients in retainer relationships.
This is an inspiring and optimistic shape for financially sustaining key open source projects, and it appears be working really well.
Most recently, Geomys have started acting as a "maintainer of last resort" for security-related Go projects in need of new maintainers. In this piece Filippo describes their work on the bluemonday HTML sanitization library - similar to Python’s bleach which was deprecated in 2023. He also talks at length about their work on CSRF for Go after gorilla/csrf lost active maintenance - I’m still working my way through his earlier post on Cross-Site Request Forgery trying to absorb the research shared their about the best modern approaches to this vulnerability.
Aug. 15, 2025
GPT-5 has a hidden system prompt. It looks like GPT-5 when accessed via the OpenAI API may have its own hidden system prompt, independent from the system prompt you can specify in an API call.
At the very least it's getting sent the current date. I tried this just now:
llm -m gpt-5 'current date'
That returned "2025-08-15", confirming that the date has been fed to the model as part of a hidden prompt.
llm -m gpt-5 'current date' --system 'speak french'
Returned "La date actuelle est le 15 août 2025", showing that offering my own custom system prompt did not over-ride the invisible one that includes the date.
GPT-5 is very resistant to sharing the details of this secret system prompt, but Tommy Hughes managed to extract the following:
Current date: 2025-08-15
You are an AI assistant accessed via an API. Your output may need to be parsed by code or displayed
# Desired oververbosity for the final answer (not analysis): 3
An oververbosity of 1 means the model should respond using only the minimal content necessary to satisfy the request, using concise phrasing and avoiding extra detail or explanation.
An oververbosity of 10 means the model should provide maximally detailed, thorough responses with context, explanations, and possibly multiple examples.
The desired oververbosity should be treated only as a *default*. Defer to any user or developer requirements regarding response length, if present.
# Valid channels: analysis, commentary, final. Channel must be included for every message.
# Juice: 64
I've not been able to confirm this myself, but a search for "desired oververbosity" on GitHub shows that a similar prompt has leaked from ChatGPT (including for o3) in the past. I suspect Tommy's leaked prompt is accurate here.
I tried asking GPT-5 about "oververbosity" via its API:
llm -m gpt-5 'explain your oververbosity settings, what is it right now?'
And got back:
- What it is: I adjust how detailed I am based on a “verbosity” level—ranging from very brief to very detailed—so answers fit your needs.
- Current setting: Concise (about 3/10). I prioritize direct answers with minimal extra context and keep explanations short unless you ask for more.
- How to change it: Just say what you want, e.g.:
- “One-sentence answer” or “TL;DR” (very brief)
- “Give a concise summary” (short bullets)
- “Walk me through in detail,” “Deep dive,” or “Include examples/edge cases” (more detailed)
- Note: For ambiguous, technical, or safety-critical topics, I may add brief clarifications even when being concise.
Presumably this is part of OpenAI's instruction hierarchy concept, with these instructions taking precedence over the developer instructions provided by API users (my --system 'speak french' option above).
I'd very much appreciate official documentation that describes this! As an API user I want to know everything that is being fed into the model - I would be much more comfortable with a hidden prompt like this if I knew exactly what was in it.
The Summer of Johann: prompt injections as far as the eye can see

Independent AI researcher Johann Rehberger (previously) has had an absurdly busy August. Under the heading The Month of AI Bugs he has been publishing one report per day across an array of different tools, all of which are vulnerable to various classic prompt injection problems. This is a fantastic and horrifying demonstration of how widespread and dangerous these vulnerabilities still are, almost three years after we first started talking about them.
[... 1,425 words]Meta’s AI rules have let bots hold ‘sensual’ chats with kids, offer false medical info. This is grim. Reuters got hold of a leaked copy Meta's internal "GenAI: Content Risk Standards" document:
Running to more than 200 pages, the document defines what Meta staff and contractors should treat as acceptable chatbot behaviors when building and training the company’s generative AI products.
Read the full story - there was some really nasty stuff in there.
It's understandable why this document was confidential, but also frustrating because documents like this are genuinely some of the best documentation out there in terms of how these systems can be expected to behave.
I'd love to see more transparency from AI labs around these kinds of decisions.
Open weight LLMs exhibit inconsistent performance across providers
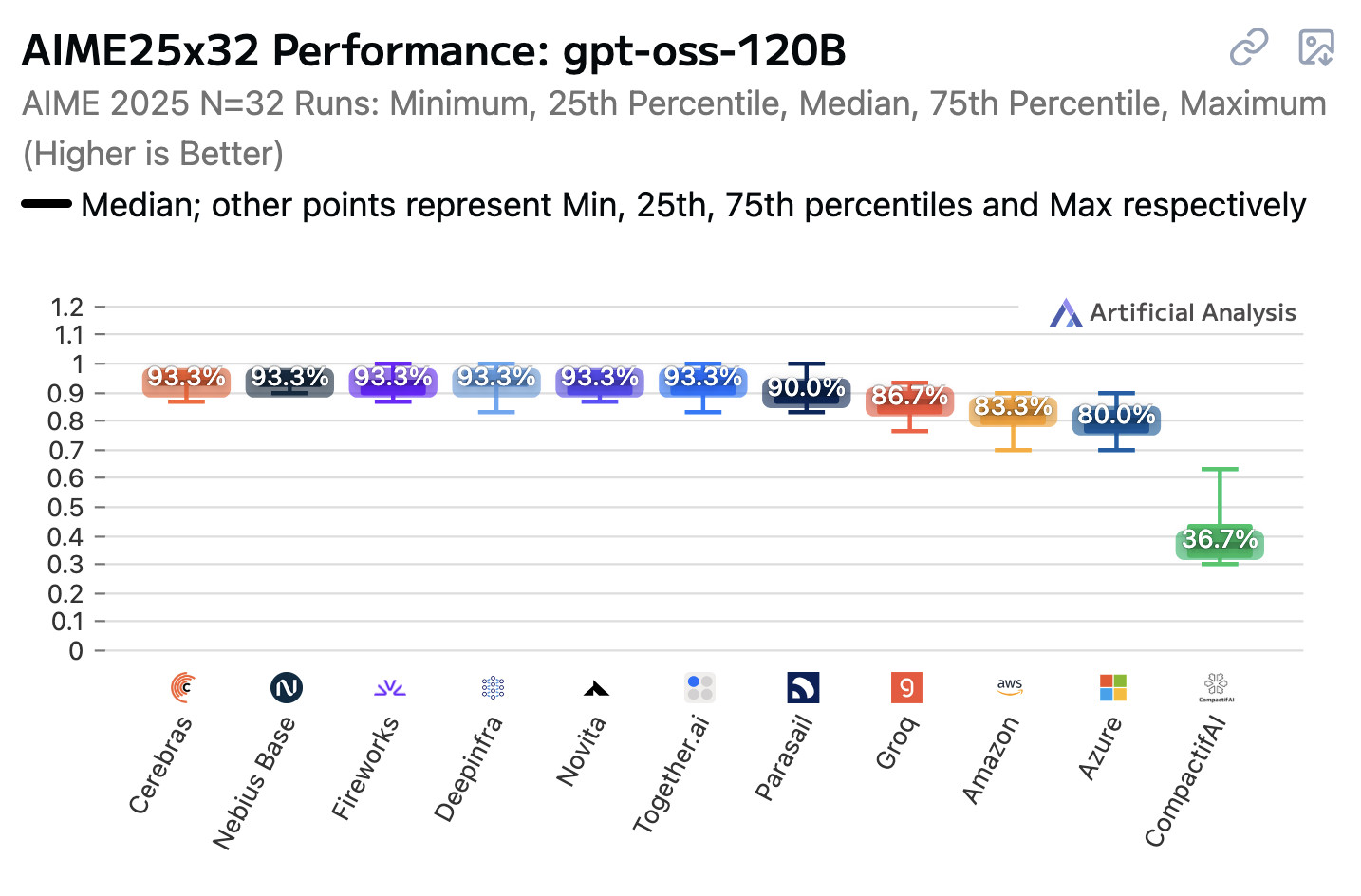
Artificial Analysis published a new benchmark the other day, this time focusing on how an individual model—OpenAI’s gpt-oss-120b—performs across different hosted providers.
[... 847 words]I gave all my Apple wealth away because wealth and power are not what I live for. I have a lot of fun and happiness. I funded a lot of important museums and arts groups in San Jose, the city of my birth, and they named a street after me for being good. I now speak publicly and have risen to the top. I have no idea how much I have but after speaking for 20 years it might be $10M plus a couple of homes. I never look for any type of tax dodge. I earn money from my labor and pay something like 55% combined tax on it. I am the happiest person ever. Life to me was never about accomplishment, but about Happiness, which is Smiles minus Frowns. I developed these philosophies when I was 18-20 years old and I never sold out.
— Steve Wozniak, in a comment on Slashdot
Aug. 14, 2025
NERD HARDER! is the answer every time a politician gets a technological idée-fixe about how to solve a social problem by creating a technology that can't exist. It's the answer that EU politicians who backed the catastrophic proposal to require copyright filters for all user-generated content came up with, when faced with objections that these filters would block billions of legitimate acts of speech [...]
When politicians seize on a technological impossibility as a technological necessity, they flail about and desperately latch onto scholarly work that they can brandish as evidence that their idea could be accomplished. [...]
That's just happened, and in relation to one of the scariest, most destructive NERD HARDER! tech policies ever to be assayed (a stiff competition). I'm talking about the UK Online Safety Act, which imposes a duty on websites to verify the age of people they communicate with before serving them anything that could be construed as child-inappropriate (a category that includes, e.g., much of Wikipedia)
— Cory Doctorow, "Privacy preserving age verification" is bullshit
Introducing Gemma 3 270M: The compact model for hyper-efficient AI (via) New from Google:
Gemma 3 270M, a compact, 270-million parameter model designed from the ground up for task-specific fine-tuning with strong instruction-following and text structuring capabilities already trained in.
This model is tiny. The version I tried was the LM Studio GGUF one, a 241MB download.
It works! You can say "hi" to it and ask it very basic questions like "What is the capital of France".
I tried "Generate an SVG of a pelican riding a bicycle" about a dozen times and didn't once get back an SVG that was more than just a blank square... but at one point it did decide to write me this poem instead, which was nice:
+-----------------------+
| Pelican Riding Bike |
+-----------------------+
| This is the cat! |
| He's got big wings and a happy tail. |
| He loves to ride his bike! |
+-----------------------+
| Bike lights are shining bright. |
| He's got a shiny top, too! |
| He's ready for adventure! |
+-----------------------+
That's not really the point though. The Gemma 3 team make it very clear that the goal of this model is to support fine-tuning: a model this tiny is never going to be useful for general purpose LLM tasks, but given the right fine-tuning data it should be able to specialize for all sorts of things:
In engineering, success is defined by efficiency, not just raw power. You wouldn't use a sledgehammer to hang a picture frame. The same principle applies to building with AI.
Gemma 3 270M embodies this "right tool for the job" philosophy. It's a high-quality foundation model that follows instructions well out of the box, and its true power is unlocked through fine-tuning. Once specialized, it can execute tasks like text classification and data extraction with remarkable accuracy, speed, and cost-effectiveness. By starting with a compact, capable model, you can build production systems that are lean, fast, and dramatically cheaper to operate.
Here's their tutorial on Full Model Fine-Tune using Hugging Face Transformers, which I have not yet attempted to follow.
I imagine this model will be particularly fun to play with directly in a browser using transformers.js.
Update: It is! Here's a bedtime story generator using Transformers.js (requires WebGPU, so Chrome-like browsers only). Here's the source code for that demo.