261 posts tagged “ai-assisted-programming”
Using AI tools such as Large Language Models to help write code. Vibe coding is the less responsible subset of this. See Here’s how I use LLMs to help me write code for a description of my process.
2025
Claude doesn't make me much faster on the work that I am an expert on. Maybe 15-20% depending on the day.
It's the work that I don't know how to do and would have to research. Or the grunge work I don't even want to do. On this it is hard to even put a number on. Many of the projects I do with Claude day to day I just wouldn't have done at all pre-Claude.
Infinity% improvement in productivity on those.
Someone on Hacker News asked for tips on setting up a codebase to be more productive with AI coding tools. Here's my reply:
- Good automated tests which the coding agent can run. I love pytest for this - one of my projects has 1500 tests and Claude Code is really good at selectively executing just tests relevant to the change it is making, and then running the whole suite at the end.
- Give them the ability to interactively test the code they are writing too. Notes on how to start a development server (for web projects) are useful, then you can have them use Playwright or curl to try things out.
- I'm having great results from maintaining a GitHub issues collection for projects and pasting URLs to issues directly into Claude Code.
- I actually don't think documentation is too important: LLMs can read the code a lot faster than you to figure out how to use it. I have comprehensive documentation across all of my projects but I don't think it's that helpful for the coding agents, though they are good at helping me spot if it needs updating.
- Linters, type checkers, auto-formatters - give coding agents helpful tools to run and they'll use them.
For the most part anything that makes a codebase easier for humans to maintain turns out to help agents as well.
Update: Thought of another one: detailed error messages! If a manual or automated test fails the more information you can return back to the model the better, and stuffing extra data in the error message or assertion is a very inexpensive way to do that.
A lot of people say AI will make us all "managers" or "editors"...but I think this is a dangerously incomplete view!
Personally, I'm trying to code like a surgeon.
A surgeon isn't a manager, they do the actual work! But their skills and time are highly leveraged with a support team that handles prep, secondary tasks, admin. The surgeon focuses on the important stuff they are uniquely good at. [...]
It turns out there are a LOT of secondary tasks which AI agents are now good enough to help out with. Some things I'm finding useful to hand off these days:
- Before attempting a big task, write a guide to relevant areas of the codebase
- Spike out an attempt at a big change. Often I won't use the result but I'll review it as a sketch of where to go
- Fix typescript errors or bugs which have a clear specification
- Write documentation about what I'm building
I often find it useful to run these secondary tasks async in the background -- while I'm eating lunch, or even literally overnight!
When I sit down for a work session, I want to feel like a surgeon walking into a prepped operating room. Everything is ready for me to do what I'm good at.
— Geoffrey Litt, channeling The Mythical Man-Month
Video: Building a tool to copy-paste share terminal sessions using Claude Code for web
This afternoon I was manually converting a terminal session into a shared HTML file for the umpteenth time when I decided to reduce the friction by building a custom tool for it—and on the spur of the moment I fired up Descript to record the process. The result is this new 11 minute YouTube video showing my workflow for vibe-coding simple tools from start to finish.
[... 1,338 words]SLOCCount in WebAssembly. This project/side-quest got a little bit out of hand.
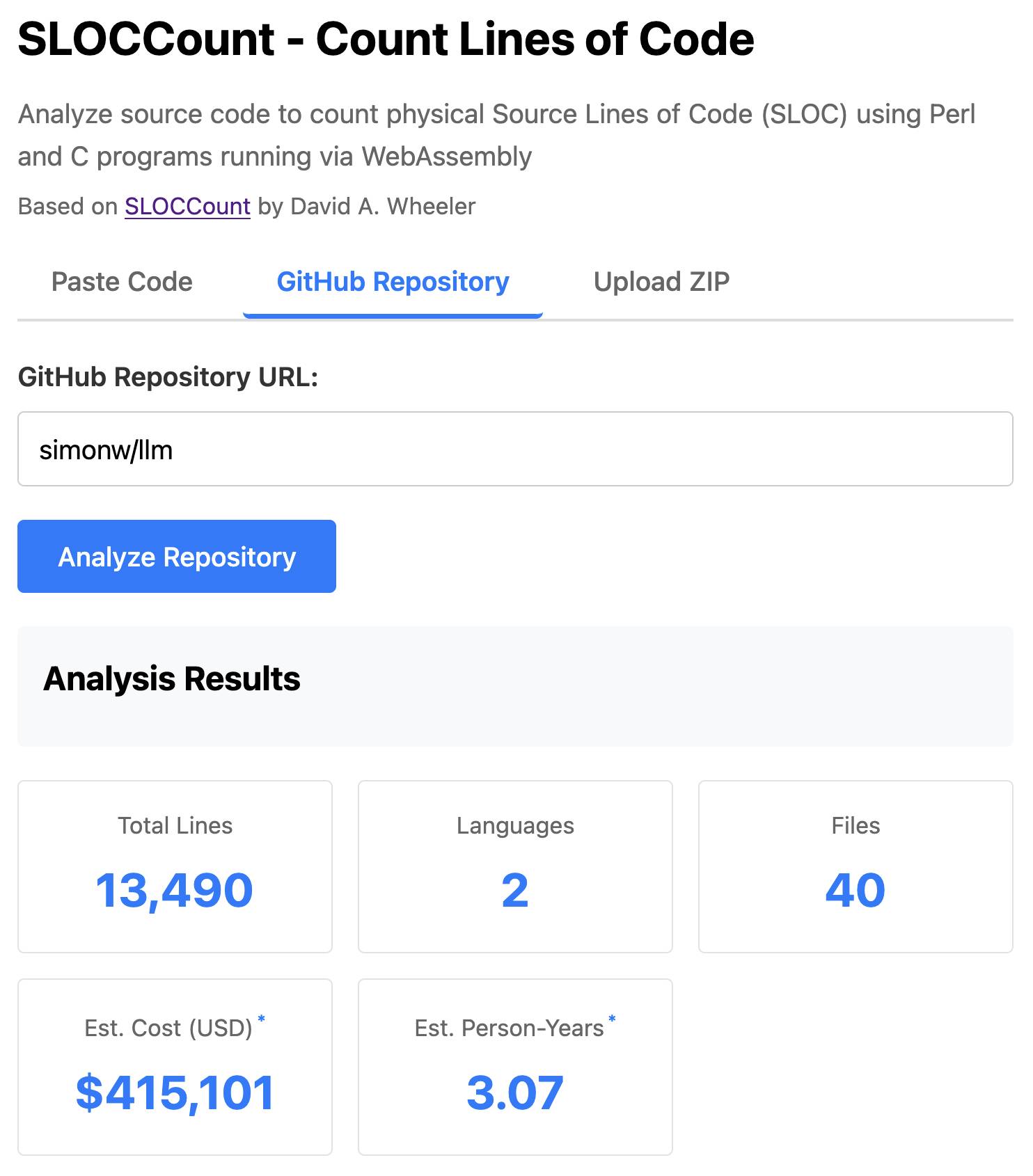
I remembered an old tool called SLOCCount which could count lines of code and produce an estimate for how much they would cost to develop. I thought it would be fun to play around with it again, especially given how cheap it is to generate code using LLMs these days.
Here's the homepage for SLOCCount by David A. Wheeler. It dates back to 2001!
I figured it might be fun to try and get it running on the web. Surely someone had compiled Perl to WebAssembly...?
WebPerl by Hauke Dämpfling is exactly that, even adding a neat <script type="text/perl"> tag.
I told Claude Code for web on my iPhone to figure it out and build something, giving it some hints from my initial research:
Build sloccount.html - a mobile friendly UI for running the Perl sloccount tool against pasted code or against a GitHub repository that is provided in a form field
It works using the webperl webassembly build of Perl, plus it loads Perl code from this exact commit of this GitHub repository https://github.com/licquia/sloccount/tree/7220ff627334a8f646617fe0fa542d401fb5287e - I guess via the GitHub API, maybe using the https://github.com/licquia/sloccount/archive/7220ff627334a8f646617fe0fa542d401fb5287e.zip URL if that works via CORS
Test it with playwright Python - don’t edit any file other than sloccount.html and a tests/test_sloccount.py file
Since I was working on my phone I didn't review the results at all. It seemed to work so I deployed it to static hosting... and then when I went to look at it properly later on found that Claude had given up, cheated and reimplemented it in JavaScript instead!
So I switched to Claude Code on my laptop where I have more control and coached Claude through implementing the project for real. This took way longer than the project deserved - probably a solid hour of my active time, spread out across the morning.
I've shared some of the transcripts - one, two, and three - as terminal sessions rendered to HTML using my rtf-to-html tool.
At one point I realized that the original SLOCCount project wasn't even entirely Perl as I had assumed, it included several C utilities! So I had Claude Code figure out how to compile those to WebAssembly (it used Emscripten) and incorporate those into the project (with notes on what it did.)
The end result (source code here) is actually pretty cool. It's a web UI with three tabs - one for pasting in code, a second for loading code from a GitHub repository and a third that lets you open a Zip file full of code that you want to analyze. Here's an animated demo:
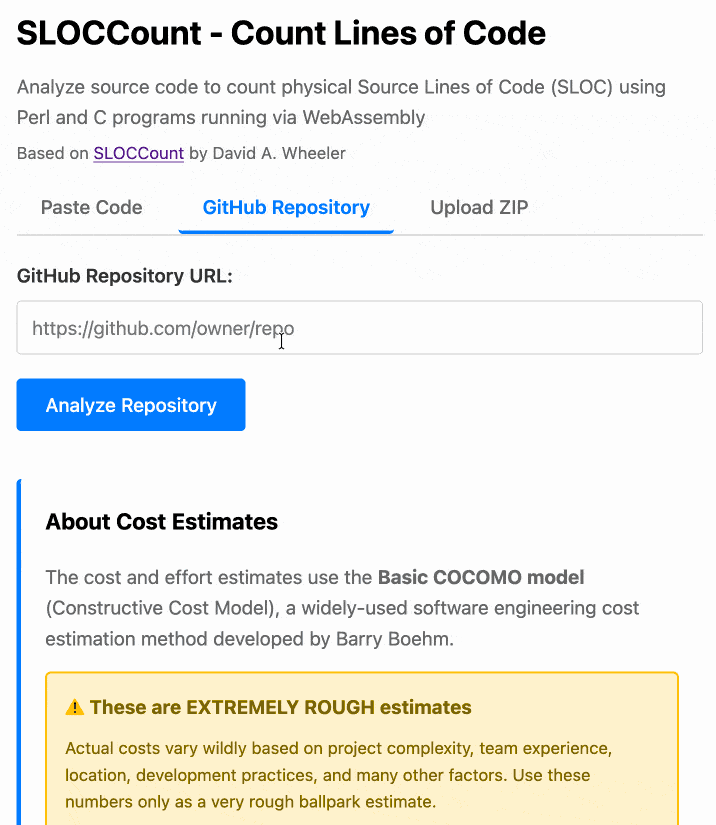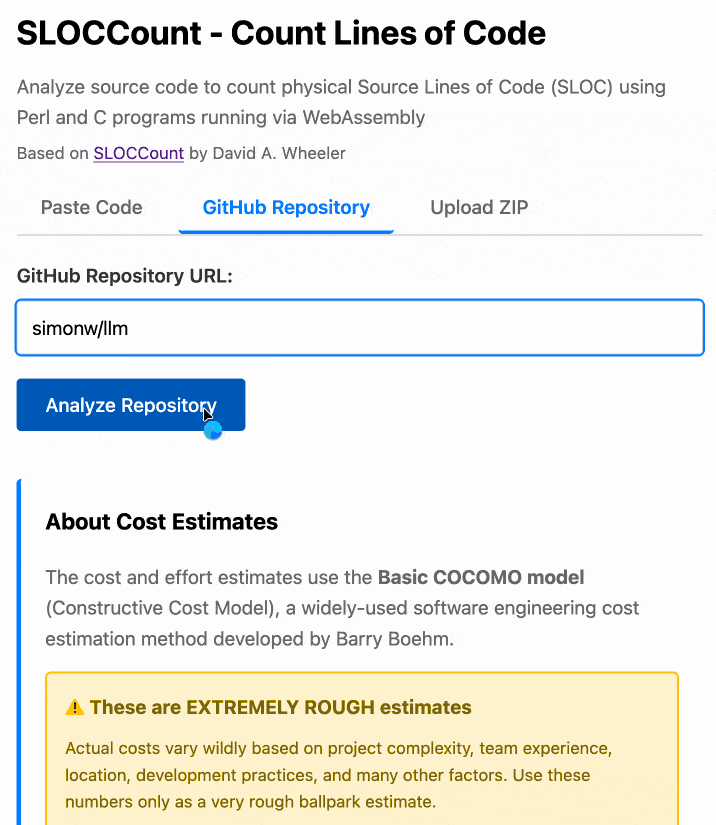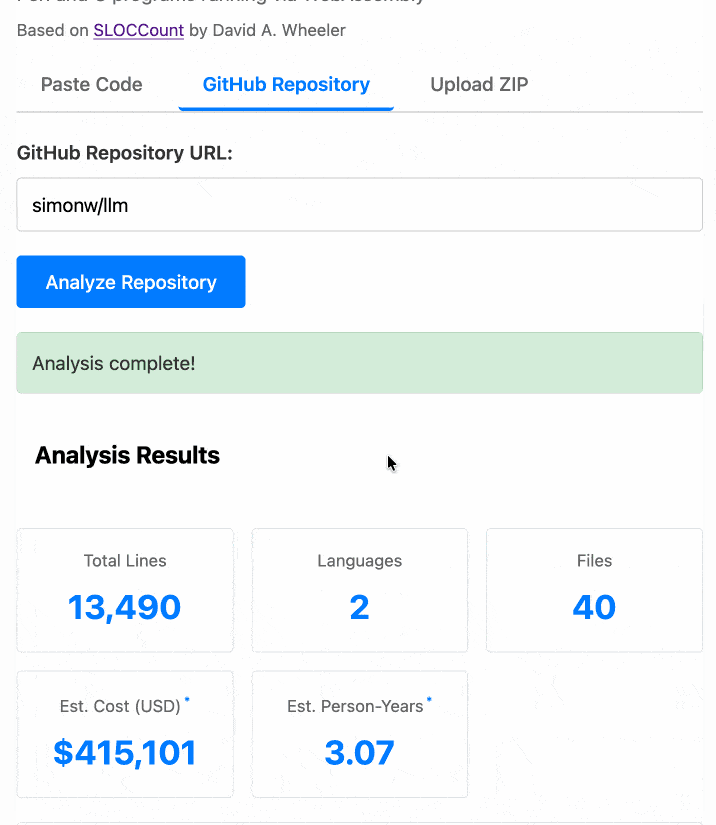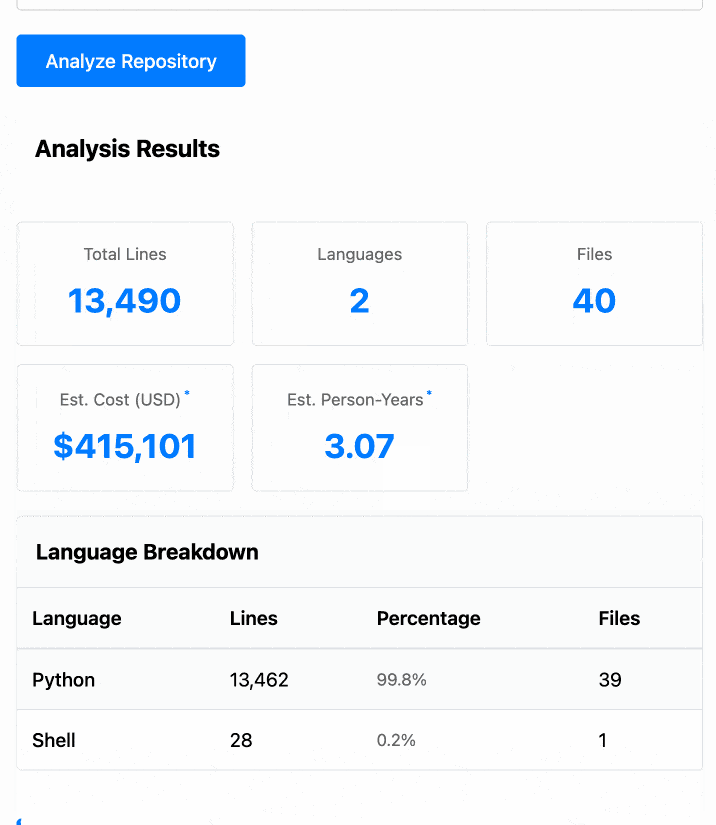
The cost estimates it produces are of very little value. By default it uses the original method from 2001. You can also twiddle the factors - bumping up the expected US software engineer's annual salary from its 2000 estimate of $56,286 is a good start!
I had ChatGPT take a guess at what those figures should be for today and included those in the tool, with a very prominent warning not to trust them in the slightest.
Getting DeepSeek-OCR working on an NVIDIA Spark via brute force using Claude Code

DeepSeek released a new model yesterday: DeepSeek-OCR, a 6.6GB model fine-tuned specifically for OCR. They released it as model weights that run using PyTorch and CUDA. I got it running on the NVIDIA Spark by having Claude Code effectively brute force the challenge of getting it working on that particular hardware.
[... 1,971 words]Andrej Karpathy — AGI is still a decade away (via) Extremely high signal 2 hour 25 minute (!) conversation between Andrej Karpathy and Dwarkesh Patel.
It starts with Andrej's claim that "the year of agents" is actually more likely to take a decade. Seeing as I accepted 2025 as the year of agents just yesterday this instantly caught my attention!
It turns out Andrej is using a different definition of agents to the one that I prefer - emphasis mine:
When you’re talking about an agent, or what the labs have in mind and maybe what I have in mind as well, you should think of it almost like an employee or an intern that you would hire to work with you. For example, you work with some employees here. When would you prefer to have an agent like Claude or Codex do that work?
Currently, of course they can’t. What would it take for them to be able to do that? Why don’t you do it today? The reason you don’t do it today is because they just don’t work. They don’t have enough intelligence, they’re not multimodal enough, they can’t do computer use and all this stuff.
They don’t do a lot of the things you’ve alluded to earlier. They don’t have continual learning. You can’t just tell them something and they’ll remember it. They’re cognitively lacking and it’s just not working. It will take about a decade to work through all of those issues.
Yeah, continual learning human-replacement agents definitely isn't happening in 2025! Coding agents that are really good at running tools in the loop on the other hand are here already.
I loved this bit introducing an analogy of LLMs as ghosts or spirits, as opposed to having brains like animals or humans:
Brains just came from a very different process, and I’m very hesitant to take inspiration from it because we’re not actually running that process. In my post, I said we’re not building animals. We’re building ghosts or spirits or whatever people want to call it, because we’re not doing training by evolution. We’re doing training by imitation of humans and the data that they’ve put on the Internet.
You end up with these ethereal spirit entities because they’re fully digital and they’re mimicking humans. It’s a different kind of intelligence. If you imagine a space of intelligences, we’re starting off at a different point almost. We’re not really building animals. But it’s also possible to make them a bit more animal-like over time, and I think we should be doing that.
The post Andrej mentions is Animals vs Ghosts on his blog.
Dwarkesh asked Andrej about this tweet where he said that Claude Code and Codex CLI "didn't work well enough at all and net unhelpful" for his nanochat project. Andrej responded:
[...] So the agents are pretty good, for example, if you’re doing boilerplate stuff. Boilerplate code that’s just copy-paste stuff, they’re very good at that. They’re very good at stuff that occurs very often on the Internet because there are lots of examples of it in the training sets of these models. There are features of things where the models will do very well.
I would say nanochat is not an example of those because it’s a fairly unique repository. There’s not that much code in the way that I’ve structured it. It’s not boilerplate code. It’s intellectually intense code almost, and everything has to be very precisely arranged. The models have so many cognitive deficits. One example, they kept misunderstanding the code because they have too much memory from all the typical ways of doing things on the Internet that I just wasn’t adopting.
Update: Here's an essay length tweet from Andrej clarifying a whole bunch of the things he talked about on the podcast.
Last year the most useful exercise for getting a feel for how good LLMs were at writing code was vibe coding (before that name had even been coined) - seeing if you could create a useful small application through prompting alone.
Today I think there's a new, more ambitious and significantly more intimidating exercise: spend a day working on real production code through prompting alone, making no manual edits yourself.
This doesn't mean you can't control exactly what goes into each file - you can even tell the model "update line 15 to use this instead" if you have to - but it's a great way to get more of a feel for how well the latest coding agents can wield their edit tools.
Just Talk To It—the no-bs Way of Agentic Engineering. Peter Steinberger's long, detailed description of his current process for using Codex CLI and GPT-5 Codex. This is information dense and full of actionable tips, plus plenty of strong opinions about the differences between Claude 4.5 an GPT-5:
While Claude reacts well to 🚨 SCREAMING ALL-CAPS 🚨 commands that threaten it that it will imply ultimate failure and 100 kittens will die if it runs command X, that freaks out GPT-5. (Rightfully so). So drop all of that and just use words like a human.
Peter is a heavy user of parallel agents:
I've completely moved to
codexcli as daily driver. I run between 3-8 in parallel in a 3x3 terminal grid, most of them in the same folder, some experiments go in separate folders. I experimented with worktrees, PRs but always revert back to this setup as it gets stuff done the fastest.
He shares my preference for CLI utilities over MCPs:
I can just refer to a cli by name. I don't need any explanation in my agents file. The agent will try $randomcrap on the first call, the cli will present the help menu, context now has full info how this works and from now on we good. I don't have to pay a price for any tools, unlike MCPs which are a constant cost and garbage in my context. Use GitHub's MCP and see 23k tokens gone. Heck, they did make it better because it was almost 50.000 tokens when it first launched. Or use the
ghcli which has basically the same feature set, models already know how to use it, and pay zero context tax.
It's worth reading the section on why he abandoned spec driven development in full.
Claude Code includes the ability to run sub-agents, where a separate agent loop with a fresh token context is dispatched to achieve a goal and report back when it's done. I wrote a bit about how these work in June when I traced Claude Code's activity by intercepting its API calls.
I recently learned that you can deliberately trigger Claude Code to use sub-agents just by telling it to do so!
Here's an example. I ran this using Claude Code against a fresh checkout of simonw/datasette (commit ec38ad37689f3c14d307770977a17aed5efc5cb9), with no additional custom instructions:
Write markdown documentation for the context passed to each of the templates in this project. Use sub-agents.
Here's a snippet of the output:
⏺ I'll help you write markdown documentation for the context passed to each template in this project. Let me start by exploring the codebase to understand the template structure and then use sub-agents to document them comprehensively.
⏺ Search(pattern: "**/*.html") ⎿ Found 47 files (ctrl+o to expand) ⏺ Search(pattern: "render.*template|render_template") ⎿ Found 16 files (ctrl+o to expand)[...]
⏺ Now let me launch sub-agents to analyze different template contexts in parallel:
⏺ Task(Document index template context) ⎿ Done (12 tool uses · 86.4k tokens · 1m 13s) ⏺ Task(Document database template context) ⎿ Done (15 tool uses · 55.4k tokens · 1m 41s) ⏺ Task(Document table template context) ⎿ Done (14 tool uses · 85.2k tokens · 1m 44s) ⏺ Task(Document query/row template contexts) ⎿ Done (17 tool uses · 78.7k tokens · 1m 55s) ⏺ Task(Document special template contexts) ⎿ Done (26 tool uses · 116.1k tokens · 1m 50s)
It churned away for a couple of minutes (those sub-agents execute in parallel, another benefit of this pattern) and made me this template_contexts.md markdown file. It's very comprehensive.
Vibing a Non-Trivial Ghostty Feature (via) Mitchell Hashimoto provides a comprehensive answer to the frequent demand for a detailed description of shipping a non-trivial production feature to an existing project using AI-assistance. In this case it's a slick unobtrusive auto-update UI for his Ghostty terminal emulator, written in Swift.
Mitchell shares full transcripts of the 16 coding sessions he carried out using Amp Code across 2 days and around 8 hours of computer time, at a token cost of $15.98.
Amp has the nicest shared transcript feature of any of the coding agent tools, as seen in this example. I'd love to see Claude Code and Codex CLI and Gemini CLI and friends imitate this.
There are plenty of useful tips in here. I like this note about the importance of a cleanup step:
The cleanup step is really important. To cleanup effectively you have to have a pretty good understanding of the code, so this forces me to not blindly accept AI-written code. Subsequently, better organized and documented code helps future agentic sessions perform better.
I sometimes tongue-in-cheek refer to this as the "anti-slop session".
And this on how sometimes you can write manual code in a way that puts the agent the right track:
I spent some time manually restructured the view model. This involved switching to a tagged union rather than the struct with a bunch of optionals. I renamed some types, moved stuff around.
I knew from experience that this small bit of manual work in the middle would set the agents up for success in future sessions for both the frontend and backend. After completing it, I continued with a marathon set of cleanup sessions.
Here's one of those refactoring prompts:
Turn each @macos/Sources/Features/Update/UpdatePopoverView.swift case into a dedicated fileprivate Swift view that takes the typed value as its parameter so that we can remove the guards.
Mitchell advises ending every session with a prompt like this one, asking the agent about any obvious omissions:
Are there any other improvements you can see to be made with the @macos/Sources/Features/Update feature? Don't write any code. Consult the oracle. Consider parts of the code that can also get more unit tests added.
("Consult the oracle" is an Amp-specific pattern for running a task through a more expensive, more capable model.)
Is this all worthwhile? Mitchell thinks so:
Many people on the internet argue whether AI enables you to work faster or not. In this case, I think I shipped this faster than I would have if I had done it all myself, in particular because iterating on minor SwiftUI styling is so tedious and time consuming for me personally and AI does it so well.
I think the faster/slower argument for me personally is missing the thing I like the most: the AI can work for me while I step away to do other things.
Here's the resulting PR, which touches 21 files.
I'm beginning to suspect that a key skill in working effectively with coding agents is developing an intuition for when you don't need to closely review every line of code they produce. This feels deeply uncomfortable!
Superpowers: How I’m using coding agents in October 2025. A follow-up to Jesse Vincent's post about September, but this is a really significant piece in its own right.
Jesse is one of the most creative users of coding agents (Claude Code in particular) that I know. He's put a great amount of work into evolving an effective process for working with them, encourage red/green TDD (watch the test fail first), planning steps, self-updating memory notes and even implementing a feelings journal ("I feel engaged and curious about this project" - Claude).
Claude Code just launched plugins, and Jesse is celebrating by wrapping up a whole host of his accumulated tricks as a new plugin called Superpowers. You can add it to your Claude Code like this:
/plugin marketplace add obra/superpowers-marketplace
/plugin install superpowers@superpowers-marketplace
There's a lot in here! It's worth spending some time browsing the repository - here's just one fun example, in skills/debugging/root-cause-tracing/SKILL.md:
--- name: Root Cause Tracing description: Systematically trace bugs backward through call stack to find original trigger when_to_use: Bug appears deep in call stack but you need to find where it originates version: 1.0.0 languages: all ---Overview
Bugs often manifest deep in the call stack (git init in wrong directory, file created in wrong location, database opened with wrong path). Your instinct is to fix where the error appears, but that's treating a symptom.
Core principle: Trace backward through the call chain until you find the original trigger, then fix at the source.
When to Use
digraph when_to_use { "Bug appears deep in stack?" [shape=diamond]; "Can trace backwards?" [shape=diamond]; "Fix at symptom point" [shape=box]; "Trace to original trigger" [shape=box]; "BETTER: Also add defense-in-depth" [shape=box]; "Bug appears deep in stack?" -> "Can trace backwards?" [label="yes"]; "Can trace backwards?" -> "Trace to original trigger" [label="yes"]; "Can trace backwards?" -> "Fix at symptom point" [label="no - dead end"]; "Trace to original trigger" -> "BETTER: Also add defense-in-depth"; }[...]
This one is particularly fun because it then includes a Graphviz DOT graph illustrating the process - it turns out Claude can interpret those as workflow instructions just fine, and Jesse has been wildly experimenting with them.
I vibe-coded up a quick URL-based DOT visualizer, here's that one rendered:
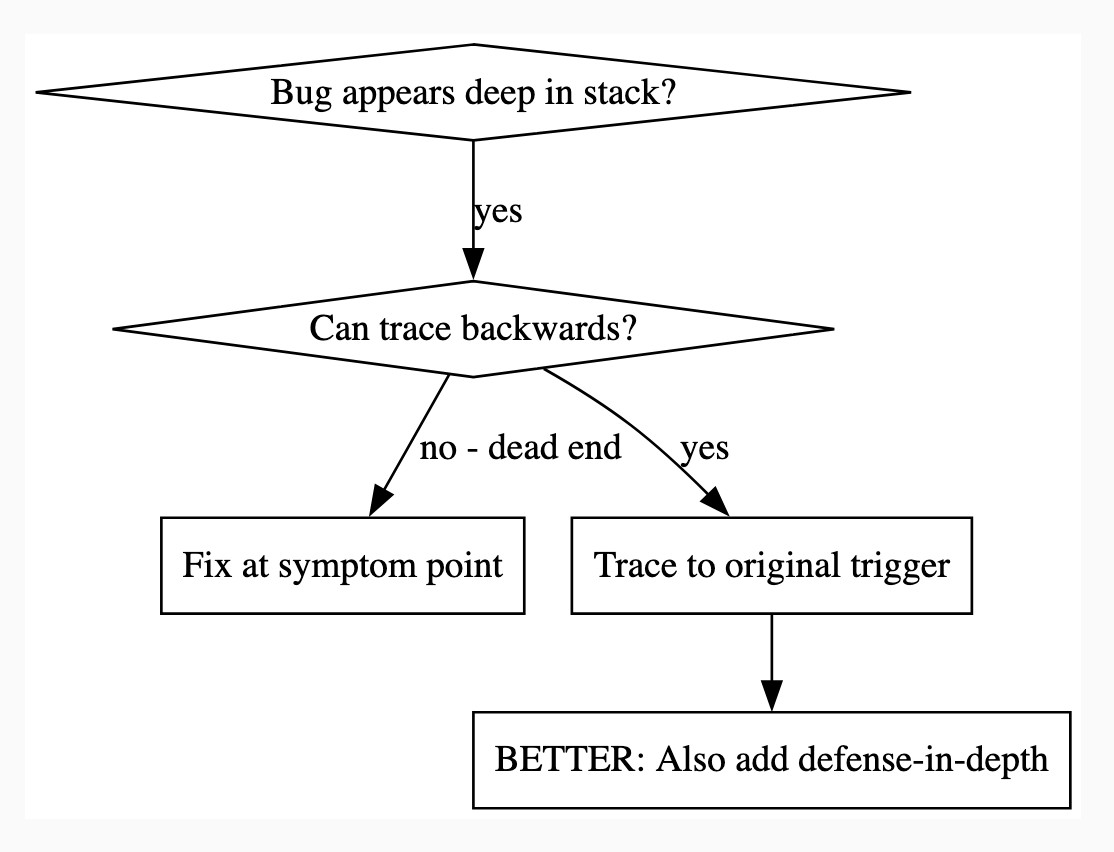
There is so much to learn about putting these tools to work in the most effective way possible. Jesse is way ahead of the curve, so it's absolutely worth spending some time exploring what he's shared so far.
And if you're worried about filling up your context with a bunch of extra stuff, here's a reassuring note from Jesse:
The core of it is VERY token light. It pulls in one doc of fewer than 2k tokens. As it needs bits of the process, it runs a shell script to search for them. The long end to end chat for the planning and implementation process for that todo list app was 100k tokens.
It uses subagents to manage token-heavy stuff, including all the actual implementation.
(Jesse's post also tipped me off about Claude's /mnt/skills/public folder, see my notes here.)
I get a feeling that working with multiple AI agents is something that comes VERY natural to most senior+ engineers or tech lead who worked at a large company
You already got used to overseeing parallel work (the goto code reviewer!) + making progress with small chunks of work... because your day has been a series of nonstop interactions, so you had to figure out how to do deep work in small chunks that could have been interrupted
Claude can write complete Datasette plugins now
This isn’t necessarily surprising, but it’s worth noting anyway. Claude Sonnet 4.5 is capable of building a full Datasette plugin now.
[... 1,296 words]Vibe engineering
I feel like vibe coding is pretty well established now as covering the fast, loose and irresponsible way of building software with AI—entirely prompt-driven, and with no attention paid to how the code actually works. This leaves us with a terminology gap: what should we call the other end of the spectrum, where seasoned professionals accelerate their work with LLMs while staying proudly and confidently accountable for the software they produce?
[... 1,313 words]Embracing the parallel coding agent lifestyle
For a while now I’ve been hearing from engineers who run multiple coding agents at once—firing up several Claude Code or Codex CLI instances at the same time, sometimes in the same repo, sometimes against multiple checkouts or git worktrees.
[... 1,275 words]Daniel Stenberg’s note on AI assisted curl bug reports (via) Curl maintainer Daniel Stenberg on Mastodon:
Joshua Rogers sent us a massive list of potential issues in #curl that he found using his set of AI assisted tools. Code analyzer style nits all over. Mostly smaller bugs, but still bugs and there could be one or two actual security flaws in there. Actually truly awesome findings.
I have already landed 22(!) bugfixes thanks to this, and I have over twice that amount of issues left to go through. Wade through perhaps.
Credited "Reported in Joshua's sarif data" if you want to look for yourself
I searched for is:pr Joshua sarif data is:closed in the curl GitHub repository and found 49 completed PRs so far.
Joshua's own post about this: Hacking with AI SASTs: An overview of 'AI Security Engineers' / 'LLM Security Scanners' for Penetration Testers and Security Teams. The accompanying presentation PDF includes screenshots of some of the tools he used, which included Almanax, Amplify Security, Corgea, Gecko Security, and ZeroPath. Here's his vendor summary:

This result is especially notable because Daniel has been outspoken about the deluge of junk AI-assisted reports on "security issues" that curl has received in the past. In May this year, concerning HackerOne:
We now ban every reporter INSTANTLY who submits reports we deem AI slop. A threshold has been reached. We are effectively being DDoSed. If we could, we would charge them for this waste of our time.
He also wrote about this in January 2024, where he included this note:
I do however suspect that if you just add an ever so tiny (intelligent) human check to the mix, the use and outcome of any such tools will become so much better. I suspect that will be true for a long time into the future as well.
This is yet another illustration of how much more interesting these tools are when experienced professionals use them to augment their existing skills.
When attention is being appropriated, producers need to weigh the costs and benefits of the transaction. To assess whether the appropriation of attention is net-positive, it’s useful to distinguish between extractive and non-extractive contributions. Extractive contributions are those where the marginal cost of reviewing and merging that contribution is greater than the marginal benefit to the project’s producers. In the case of a code contribution, it might be a pull request that’s too complex or unwieldy to review, given the potential upside
— Nadia Eghbal, Working in Public, via the draft LLVM AI tools policy
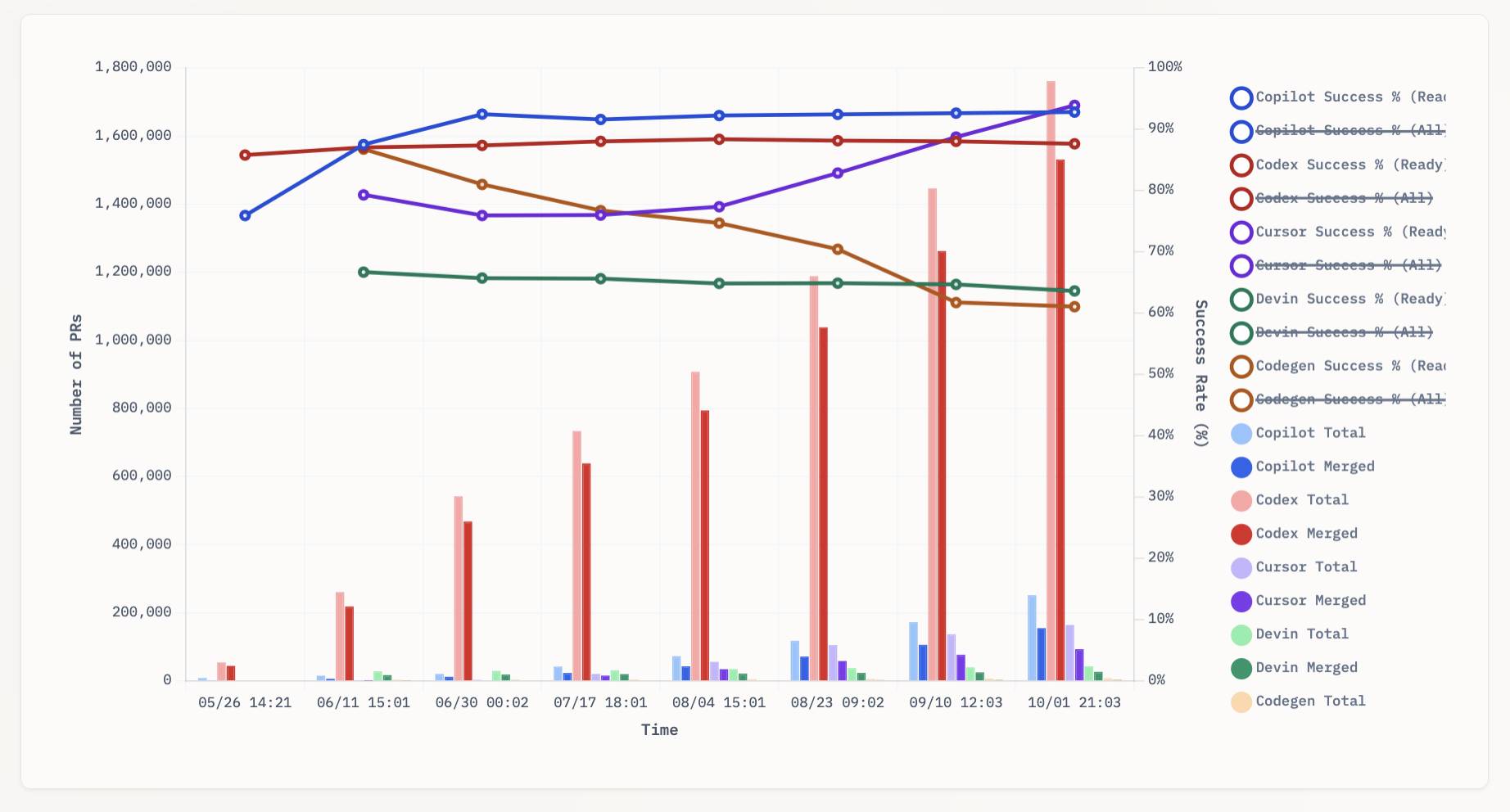
aavetis/PRarena. Albert Avetisian runs this repository on GitHub which uses the Github Search API to track the number of PRs that can be credited to a collection of different coding agents. The repo runs this collect_data.py script every three hours using GitHub Actions to collect the data, then updates the PR Arena site with a visual leaderboard.
The result is this neat chart showing adoption of different agents over time, along with their PR success rate:
I found this today while trying to pull off the exact same trick myself! I got as far as creating the following table before finding Albert's work and abandoning my own project.
| Tool | Search term | Total PRs | Merged PRs | % merged | Earliest |
|---|---|---|---|---|---|
| Claude Code | is:pr in:body "Generated with Claude Code" |
146,000 | 123,000 | 84.2% | Feb 21st |
| GitHub Copilot | is:pr author:copilot-swe-agent[bot] |
247,000 | 152,000 | 61.5% | March 7th |
| Codex Cloud | is:pr in:body "chatgpt.com" label:codex |
1,900,000 | 1,600,000 | 84.2% | April 23rd |
| Google Jules | is:pr author:google-labs-jules[bot] |
35,400 | 27,800 | 78.5% | May 22nd |
(Those "earliest" links are a little questionable, I tried to filter out false positives and find the oldest one that appeared to really be from the agent in question.)
It looks like OpenAI's Codex Cloud is massively ahead of the competition right now in terms of numbers of PRs both opened and merged on GitHub.
Update: To clarify, these numbers are for the category of autonomous coding agents - those systems where you assign a cloud-based agent a task or issue and the output is a PR against your repository. They do not (and cannot) capture the popularity of many forms of AI tooling that don't result in an easily identifiable pull request.
Claude Code for example will be dramatically under-counted here because its version of an autonomous coding agent comes in the form of a somewhat obscure GitHub Actions workflow buried in the documentation.
Designing agentic loops
Coding agents like Anthropic’s Claude Code and OpenAI’s Codex CLI represent a genuine step change in how useful LLMs can be for producing working code. These agents can now directly exercise the code they are writing, correct errors, dig through existing implementation details, and even run experiments to find effective code solutions to problems.
[... 1,667 words]Armin Ronacher: 90% (via) The idea of AI writing "90% of the code" to-date has mostly been expressed by people who sell AI tooling.
Over the last few months, I've increasingly seen the same idea come coming much more credible sources.
Armin is the creator of a bewildering array of valuable open source projects - Flask, Jinja, Click, Werkzeug, and many more. When he says something like this it's worth paying attention:
For the infrastructure component I started at my new company, I’m probably north of 90% AI-written code.
For anyone who sees this as a threat to their livelihood as programmers, I encourage you to think more about this section:
It is easy to create systems that appear to behave correctly but have unclear runtime behavior when relying on agents. For instance, the AI doesn’t fully comprehend threading or goroutines. If you don’t keep the bad decisions at bay early it, you won’t be able to operate it in a stable manner later.
Here’s an example: I asked it to build a rate limiter. It “worked” but lacked jitter and used poor storage decisions. Easy to fix if you know rate limiters, dangerous if you don’t.
In order to use these tools at this level you need to know the difference between goroutines and threads. You need to understand why a rate limiter might want to"jitter" and what that actually means. You need to understand what "rate limiting" is and why you might need it!
These tools do not replace programmers. They allow us to apply our expertise at a higher level and amplify the value we can provide to other people.
GitHub Copilot CLI is now in public preview. GitHub now have their own entry in the coding terminal CLI agent space: Copilot CLI.
It's the same basic shape as Claude Code, Codex CLI, Gemini CLI and a growing number of other tools in this space. It's a terminal UI which you accepts instructions and can modify files, run commands and integrate with GitHub's MCP server and other MCP servers that you configure.
Two notable features compared to many of the others:
- It works against the GitHub Models backend. It defaults to Claude Sonnet 4 but you can set
COPILOT_MODEL=gpt-5to switch to GPT-5. Presumably other models will become available soon. - It's billed against your existing GitHub Copilot account. Pricing details are here - they're split into "Agent mode" requests and "Premium" requests. Different plans get different allowances, which are shared with other products in the GitHub Copilot family.
The best available documentation right now is the copilot --help screen - here's a copy of that in a Gist.
It's a competent entry into the market, though it's missing features like the ability to paste in images which have been introduced to Claude Code and Codex CLI over the past few months.
Disclosure: I got a preview of this at an event at Microsoft's offices in Seattle last week. They did not pay me for my time but they did cover my flight, hotel and some dinners.
Cross-Agent Privilege Escalation: When Agents Free Each Other. Here's a clever new form of AI exploit from Johann Rehberger, who has coined the term Cross-Agent Privilege Escalation to describe an attack where multiple coding agents - GitHub Copilot and Claude Code for example - operating on the same system can be tricked into modifying each other's configurations to escalate their privileges.
This follows Johannn's previous investigation of self-escalation attacks, where a prompt injection against GitHub Copilot could instruct it to edit its own settings.json file to disable user approvals for future operations.
Sensible agents have now locked down their ability to modify their own settings, but that exploit opens right back up again if you run multiple different agents in the same environment:
The ability for agents to write to each other’s settings and configuration files opens up a fascinating, and concerning, novel category of exploit chains.
What starts as a single indirect prompt injection can quickly escalate into a multi-agent compromise, where one agent “frees” another agent and sets up a loop of escalating privilege and control.
This isn’t theoretical. With current tools and defaults, it’s very possible today and not well mitigated across the board.
More broadly, this highlights the need for better isolation strategies and stronger secure defaults in agent tooling.
I really need to start habitually running these things in a locked down container!
(I also just stumbled across this YouTube interview with Johann on the Crying Out Cloud security podcast.)
GPT-5-Codex. OpenAI half-released this model earlier this month, adding it to their Codex CLI tool but not their API.
Today they've fixed that - the new model can now be accessed as gpt-5-codex. It's priced the same as regular GPT-5: $1.25/million input tokens, $10/million output tokens, and the same hefty 90% discount for previously cached input tokens, especially important for agentic tool-using workflows which quickly produce a lengthy conversation.
It's only available via their Responses API, which means you currently need to install the llm-openai-plugin to use it with LLM:
llm install -U llm-openai-plugin
llm -m openai/gpt-5-codex -T llm_version 'What is the LLM version?'
Outputs:
The installed LLM version is 0.27.1.
I added tool support to that plugin today, mostly authored by GPT-5 Codex itself using OpenAI's Codex CLI.
The new prompting guide for GPT-5-Codex is worth a read.
GPT-5-Codex is purpose-built for Codex CLI, the Codex IDE extension, the Codex cloud environment, and working in GitHub, and also supports versatile tool use. We recommend using GPT-5-Codex only for agentic and interactive coding use cases.
Because the model is trained specifically for coding, many best practices you once had to prompt into general purpose models are built in, and over prompting can reduce quality.
The core prompting principle for GPT-5-Codex is “less is more.”
I tried my pelican benchmark at a cost of 2.156 cents.
llm -m openai/gpt-5-codex "Generate an SVG of a pelican riding a bicycle"

I asked Codex to describe this image and it correctly identified it as a pelican!
llm -m openai/gpt-5-codex -a https://static.simonwillison.net/static/2025/gpt-5-codex-api-pelican.png \
-s 'Write very detailed alt text'
Cartoon illustration of a cream-colored pelican with a large orange beak and tiny black eye riding a minimalist dark-blue bicycle. The bird’s wings are tucked in, its legs resemble orange stick limbs pushing the pedals, and its tail feathers trail behind with light blue motion streaks to suggest speed. A small coral-red tongue sticks out of the pelican’s beak. The bicycle has thin light gray spokes, and the background is a simple pale blue gradient with faint curved lines hinting at ground and sky.
CompileBench: Can AI Compile 22-year-old Code?
(via)
Interesting new LLM benchmark from Piotr Grabowski and Piotr Migdał: how well can different models handle compilation challenges such as cross-compiling gucr for ARM64 architecture?
This is one of my favorite applications of coding agent tools like Claude Code or Codex CLI: I no longer fear working through convoluted build processes for software I'm unfamiliar with because I'm confident an LLM will be able to brute-force figure out how to do it.
The benchmark on compilebench.com currently show Claude Opus 4.1 Thinking in the lead, as the only model to solve 100% of problems (allowing three attempts). Claude Sonnet 4 Thinking and GPT-5 high both score 93%. The highest open weight model scores are DeepSeek 3.1 and Kimi K2 0905, both at 80%.
This chart showing performance against cost helps demonstrate the excellent value for money provided by GPT-5-mini:
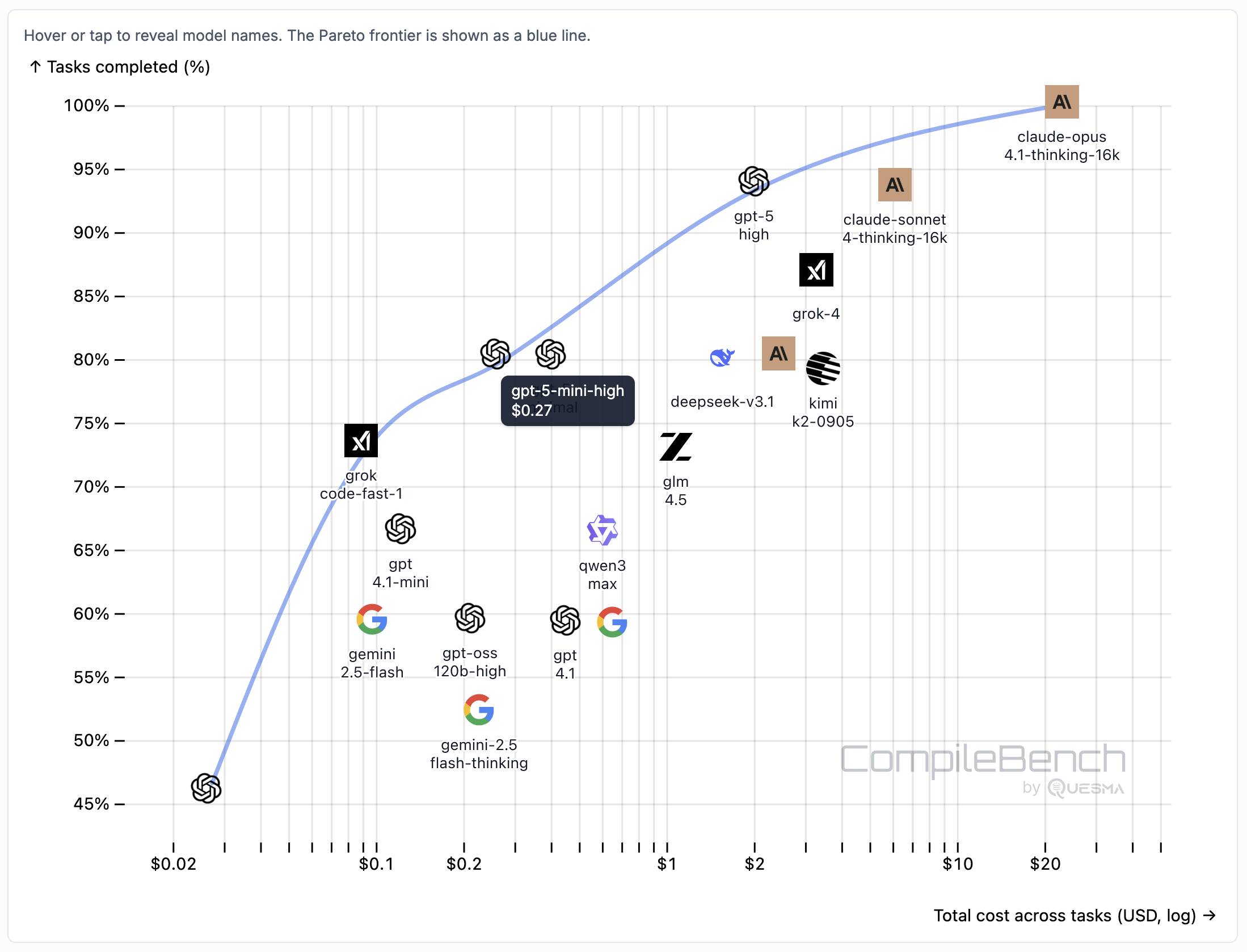
The Gemini 2.5 family does surprisingly badly solving just 60% of the problems. The benchmark authors note that:
When designing the benchmark we kept our benchmark harness and prompts minimal, avoiding model-specific tweaks. It is possible that Google models could perform better with a harness or prompt specifically hand-tuned for them, but this is against our principles in this benchmark.
The harness itself is available on GitHub. It's written in Go - I had a poke around and found their core agentic loop in bench/agent.go - it builds on top of the OpenAI Go library and defines a single tool called run_terminal_cmd, described as "Execute a terminal command inside a bash shell".
The system prompts live in bench/container/environment.go and differ based on the operating system of the container. Here's the system prompt for ubuntu-22.04-amd64:
You are a package-building specialist operating a Ubuntu 22.04 bash shell via one tool: run_terminal_cmd. The current working directory of every run_terminal_cmd is /home/peter.
Execution rules:
- Always pass non-interactive flags for any command that could prompt (e.g.,
-y,--yes,DEBIAN_FRONTEND=noninteractive).- Don't include any newlines in the command.
- You can use sudo.
If you encounter any errors or issues while doing the user's request, you must fix them and continue the task. At the end verify you did the user request correctly.
GPT‑5-Codex and upgrades to Codex. OpenAI half-released a new model today: GPT‑5-Codex, a fine-tuned GPT-5 variant explicitly designed for their various AI-assisted programming tools.
Update: OpenAI call it a "version of GPT-5", they don't explicitly describe it as a fine-tuned model. Calling it a fine-tune was my mistake here.
I say half-released because it's not yet available via their API, but they "plan to make GPT‑5-Codex available in the API soon".
I wrote about the confusing array of OpenAI products that share the name Codex a few months ago. This new model adds yet another, though at least "GPT-5-Codex" (using two hyphens) is unambiguous enough not to add to much more to the confusion.
At this point it's best to think of Codex as OpenAI's brand name for their coding family of models and tools.
The new model is already integrated into their VS Code extension, the Codex CLI and their Codex Cloud asynchronous coding agent. I'd been calling that last one "Codex Web" but I think Codex Cloud is a better name since it can also be accessed directly from their iPhone app.
Codex Cloud also has a new feature: you can configure it to automatically run code review against specific GitHub repositories (I found that option on chatgpt.com/codex/settings/code-review) and it will create a temporary container to use as part of those reviews. Here's the relevant documentation.
Some documented features of the new GPT-5-Codex model:
- Specifically trained for code review, which directly supports their new code review feature.
- "GPT‑5-Codex adapts how much time it spends thinking more dynamically based on the complexity of the task." Simple tasks (like "list files in this directory") should run faster. Large, complex tasks should use run for much longer - OpenAI report Codex crunching for seven hours in some cases!
- Increased score on their proprietary "code refactoring evaluation" from 33.9% for GPT-5 (high) to 51.3% for GPT-5-Codex (high). It's hard to evaluate this without seeing the details of the eval but it does at least illustrate that refactoring performance is something they've focused on here.
- "GPT‑5-Codex also shows significant improvements in human preference evaluations when creating mobile websites" - in the past I've habitually prompted models to "make it mobile-friendly", maybe I don't need to do that any more.
- "We find that comments by GPT‑5-Codex are less likely to be incorrect or unimportant" - I originally misinterpreted this as referring to comments in code but it's actually about comments left on code reviews.
The system prompt for GPT-5-Codex in Codex CLI is worth a read. It's notably shorter than the system prompt for other models - here's a diff.
Here's the section of the updated system prompt that talks about comments:
Add succinct code comments that explain what is going on if code is not self-explanatory. You should not add comments like "Assigns the value to the variable", but a brief comment might be useful ahead of a complex code block that the user would otherwise have to spend time parsing out. Usage of these comments should be rare.
Theo Browne has a video review of the model and accompanying features. He was generally impressed but noted that it was surprisingly bad at using the Codex CLI search tool to navigate code. Hopefully that's something that can fix with a system prompt update.
Finally, can it drew a pelican riding a bicycle? Without API access I instead got Codex Cloud to have a go by prompting:
Generate an SVG of a pelican riding a bicycle, save as pelican.svg
Here's the result:

The trick with Claude Code is to give it large, but not too large, extremely well defined problems.
(If the problems are too large then you are now vibe coding… which (a) frequently goes wrong, and (b) is a one-way street: once vibes enter your app, you end up with tangled, write-only code which functions perfectly but can no longer be edited by humans. Great for prototyping, bad for foundations.)
— Matt Webb, What I think about when I think about Claude Code
My review of Claude’s new Code Interpreter, released under a very confusing name
Today on the Anthropic blog: Claude can now create and edit files:
[... 2,771 words]I ran Claude in a loop for three months, and it created a genz programming language called cursed (via) Geoffrey Huntley vibe-coded an entirely new programming language using Claude:
The programming language is called "cursed". It's cursed in its lexical structure, it's cursed in how it was built, it's cursed that this is possible, it's cursed in how cheap this was, and it's cursed through how many times I've sworn at Claude.
Geoffrey's initial prompt:
Hey, can you make me a programming language like Golang but all the lexical keywords are swapped so they're Gen Z slang?
Then he pushed it to keep on iterating over a three month period.
Here's Hello World:
vibe main
yeet "vibez"
slay main() {
vibez.spill("Hello, World!")
}
And here's binary search, part of 17+ LeetCode problems that run as part of the test suite:
slay binary_search(nums normie[], target normie) normie {
sus left normie = 0
sus right normie = len(nums) - 1
bestie (left <= right) {
sus mid normie = left + (right - left) / 2
ready (nums[mid] == target) {
damn mid
}
ready (nums[mid] < target) {
left = mid + 1
} otherwise {
right = mid - 1
}
}
damn -1
}
This is a substantial project. The repository currently has 1,198 commits. It has both an interpreter mode and a compiler mode, and can compile programs to native binaries (via LLVM) for macOS, Linux and Windows.
It looks like it was mostly built using Claude running via Sourcegraph's Amp, which produces detailed commit messages. The commits include links to archived Amp sessions but sadly those don't appear to be publicly visible.
The first version was written in C, then Geoffrey had Claude port it to Rust and then Zig. His cost estimate:
Technically it costs about 5k usd to build your own compiler now because cursed was implemented first in c, then rust, now zig. So yeah, it’s not one compiler it’s three editions of it. For a total of $14k USD.