113 posts tagged “mozilla”
2025
gov.uscourts.dcd.223205.1436.0_1.pdf (via) Here's the 230 page PDF ruling on the 2023 United States v. Google LLC federal antitrust case - the case that could have resulted in Google selling off Chrome and cutting most of Mozilla's funding.
I made it through the first dozen pages - it's actually quite readable.
It opens with a clear summary of the case so far, bold highlights mine:
Last year, this court ruled that Defendant Google LLC had violated Section 2 of the Sherman Act: “Google is a monopolist, and it has acted as one to maintain its monopoly.” The court found that, for more than a decade, Google had entered into distribution agreements with browser developers, original equipment manufacturers, and wireless carriers to be the out-of-the box, default general search engine (“GSE”) at key search access points. These access points were the most efficient channels for distributing a GSE, and Google paid billions to lock them up. The agreements harmed competition. They prevented rivals from accumulating the queries and associated data, or scale, to effectively compete and discouraged investment and entry into the market. And they enabled Google to earn monopoly profits from its search text ads, to amass an unparalleled volume of scale to improve its search product, and to remain the default GSE without fear of being displaced. Taken together, these agreements effectively “froze” the search ecosystem, resulting in markets in which Google has “no true competitor.”
There's an interesting generative AI twist: when the case was first argued in 2023 generative AI wasn't an influential issue, but more recently Google seem to be arguing that it is an existential threat that they need to be able to take on without additional hindrance:
The emergence of GenAl changed the course of this case. No witness at the liability trial testified that GenAl products posed a near-term threat to GSEs. The very first witness at the remedies hearing, by contrast, placed GenAl front and center as a nascent competitive threat. These remedies proceedings thus have been as much about promoting competition among GSEs as ensuring that Google’s dominance in search does not carry over into the GenAlI space. Many of Plaintiffs’ proposed remedies are crafted with that latter objective in mind.
I liked this note about the court's challenges in issuing effective remedies:
Notwithstanding this power, courts must approach the task of crafting remedies with a healthy dose of humility. This court has done so. It has no expertise in the business of GSEs, the buying and selling of search text ads, or the engineering of GenAl technologies. And, unlike the typical case where the court’s job is to resolve a dispute based on historic facts, here the court is asked to gaze into a crystal ball and look to the future. Not exactly a judge’s forte.
On to the remedies. These ones looked particularly important to me:
- Google will be barred from entering or maintaining any exclusive contract relating to the distribution of Google Search, Chrome, Google Assistant, and the Gemini app. [...]
- Google will not be required to divest Chrome; nor will the court include a contingent divestiture of the Android operating system in the final judgment. Plaintiffs overreached in seeking forced divesture of these key assets, which Google did not use to effect any illegal restraints. [...]
I guess Perplexity won't be buying Chrome then!
- Google will not be barred from making payments or offering other consideration to distribution partners for preloading or placement of Google Search, Chrome, or its GenAl products. Cutting off payments from Google almost certainly will impose substantial —in some cases, crippling— downstream harms to distribution partners, related markets, and consumers, which counsels against a broad payment ban.
That looks like a huge sigh of relief for Mozilla, who were at risk of losing a sizable portion of their income if Google's search distribution revenue were to be cut off.
Shipping WebGPU on Windows in Firefox 141 (via) WebGPU is coming to Mac and Linux soon as well:
Although Firefox 141 enables WebGPU only on Windows, we plan to ship WebGPU on Mac and Linux in the coming months, and finally on Android.
From this article I learned that it's already available in Firefox Nightly:
Note that WebGPU has been available in Firefox Nightly on all platforms other than Android for quite some time.
I tried the most recent Nightly on my Mac and now the Github Issue Generator running locally w/ SmolLM2 & WebGPU demo (previously) works! Firefox stable gives me an error message saying "Error: WebGPU is not supported in your current environment, but it is necessary to run the WebLLM engine."
The Firefox implementation is based on wgpu, an open source Rust WebGPU library.
Default styles for h1 elements are changing
(via)
Wow, this is a rare occurrence! Firefox are rolling out a change to the default user-agent stylesheet for nested <h1> elements, currently ramping from 5% to 50% of users and with full roll-out planned for Firefox 140 in June 2025. Chrome is showing deprecation warnings and Safari are expected to follow suit in the future.
What's changing? The default sizes of <h1> elements that are nested inside <article>, <aside>, <nav> and <section>.
These are the default styles being removed:
/* where x is :is(article, aside, nav, section) */ x h1 { margin-block: 0.83em; font-size: 1.50em; } x x h1 { margin-block: 1.00em; font-size: 1.17em; } x x x h1 { margin-block: 1.33em; font-size: 1.00em; } x x x x h1 { margin-block: 1.67em; font-size: 0.83em; } x x x x x h1 { margin-block: 2.33em; font-size: 0.67em; }
The short version is that, many years ago, the HTML spec introduced the idea that an <h1> within a nested section should have the same meaning (and hence visual styling) as an <h2>. This never really took off and wasn't reflected by the accessibility tree, and was removed from the HTML spec in 2022. The browsers are now trying to cleanup the legacy default styles.
This advice from that post sounds sensible to me:
- Do not rely on default browser styles for conveying a heading hierarchy. Explicitly define your document hierarchy using
<h2>for second-level headings,<h3>for third-level, etc.- Always define your own
font-sizeandmarginfor<h1>elements.
2024
MDN Browser Support Timelines. I complained on Hacker News today that I wished the MDN browser compatibility ables - like this one for the Web Locks API - included an indication as to when each browser was released rather than just the browser numbers.
It turns out they do! If you click on each browser version in turn you can see an expanded area showing the browser release date:
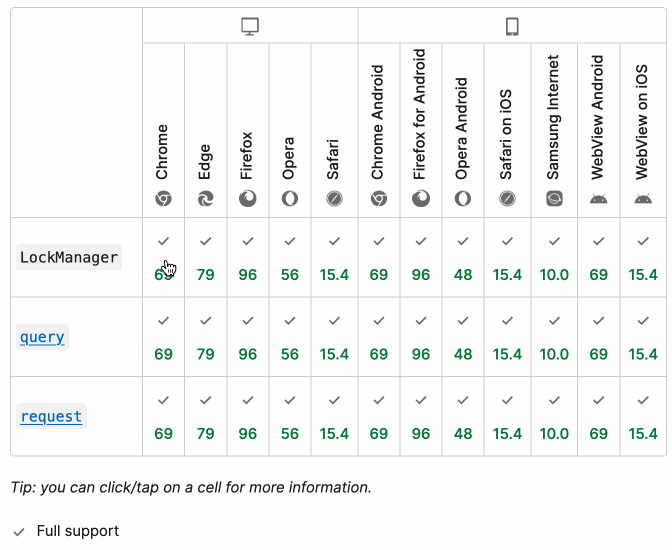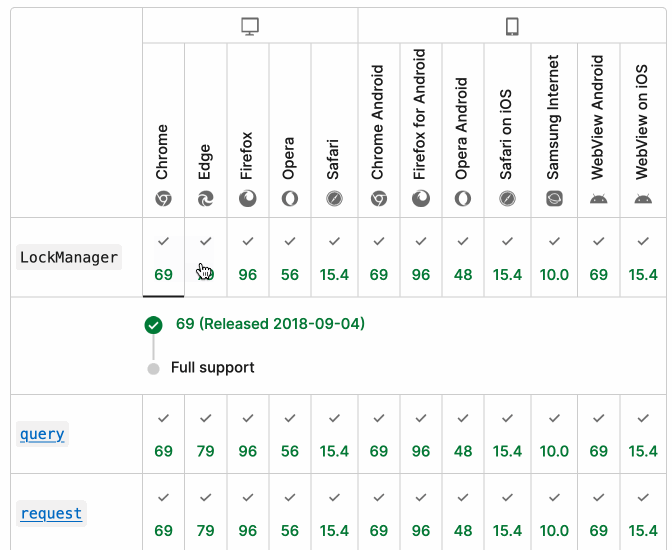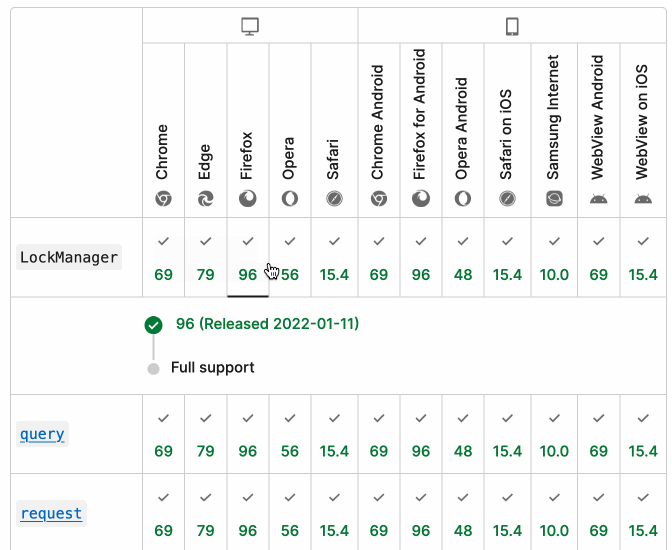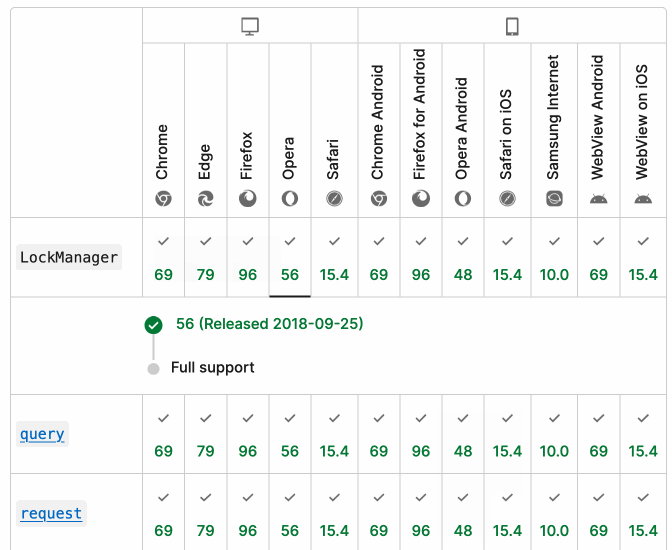
There's even an inline help tip telling you about the feature, which I've been studiously ignoring for years.
I want to see all the information at once without having to click through each browser. I had a poke around in the Firefox network tab and found https://bcd.developer.mozilla.org/bcd/api/v0/current/api.Lock.json - a JSON document containing browser support details (with release dates) for that API... and it was served using access-control-allow-origin: * which means I can hit it from my own little client-side applications.
I decided to build something with an autocomplete drop-down interface for selecting the API. That meant I'd need a list of all of the available APIs, and I used GitHub code search to find that in the mdn/browser-compat-data repository, in the api/ directory.
I needed the list of files in that directory for my autocomplete. Since there are just over 1,000 of those the regular GitHub contents API won't return them all, so I switched to the tree API instead.
Here's the finished tool - source code here:
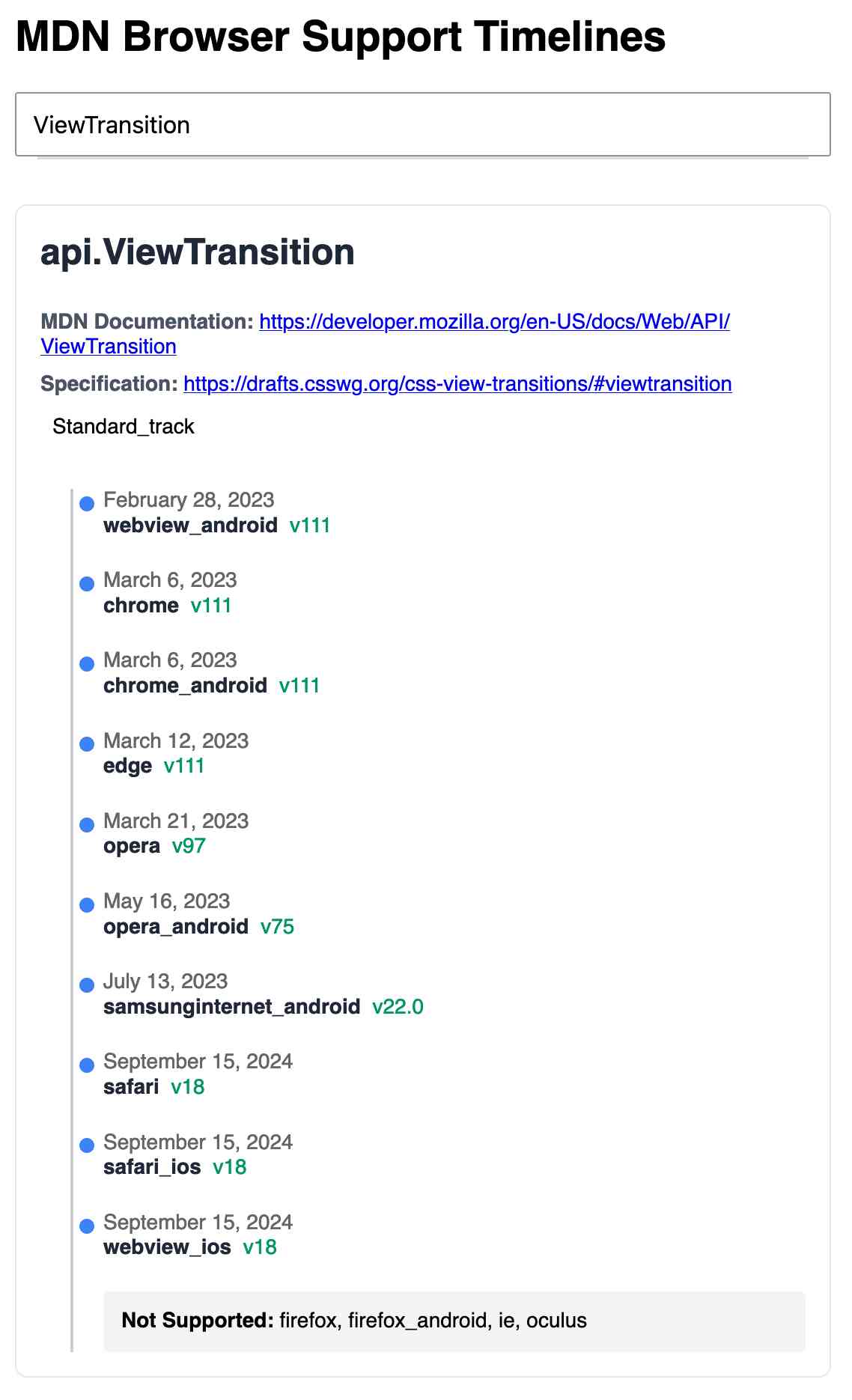
95% of the code was written by LLMs, but I did a whole lot of assembly and iterating to get it to the finished state. Three of the transcripts for that:
- Web Locks API Browser Support Timeline in which I paste in the original API JSON and ask it to come up with a timeline visualization for it.
- Enhancing API Feature Display with URL Hash where I dumped in a more complex JSON example to get it to show multiple APIs on the same page, and also had it add
#fragmentbookmarking to the tool - Fetch GitHub API Data Hierarchy where I got it to write me an async JavaScript function for fetching a directory listing from that tree API.
In 2021 we [the Mozilla engineering team] found “samesite=lax by default” isn’t shippable without what you call the “two minute twist” - you risk breaking a lot of websites. If you have that kind of two-minute exception, a lot of exploits that were supposed to be prevented remain possible.
When we tried rolling it out, we had to deal with a lot of broken websites: Debugging cookie behavior in website backends is nontrivial from a browser.
Firefox also had a prototype of what I believe is a better protection (including additional privacy benefits) already underway (called total cookie protection).
Given all of this, we paused samesite lax by default development in favor of this.
Experimenting with local alt text generation in Firefox Nightly (via) The PDF editor in Firefox (confession: I did not know Firefox ships with a PDF editor) is getting an experimental feature that can help suggest alt text for images for the human editor to then adapt and improve on.
This is a great application of AI, made all the more interesting here because Firefox will run a local model on-device for this, using a custom trained model they describe as "our 182M parameters model using a Distilled version of GPT-2 alongside a Vision Transformer (ViT) image encoder".
The model uses WebAssembly with ONNX running in Transfomers.js, and will be downloaded the first time the feature is put to use.
2023
llamafile is the new best way to run an LLM on your own computer
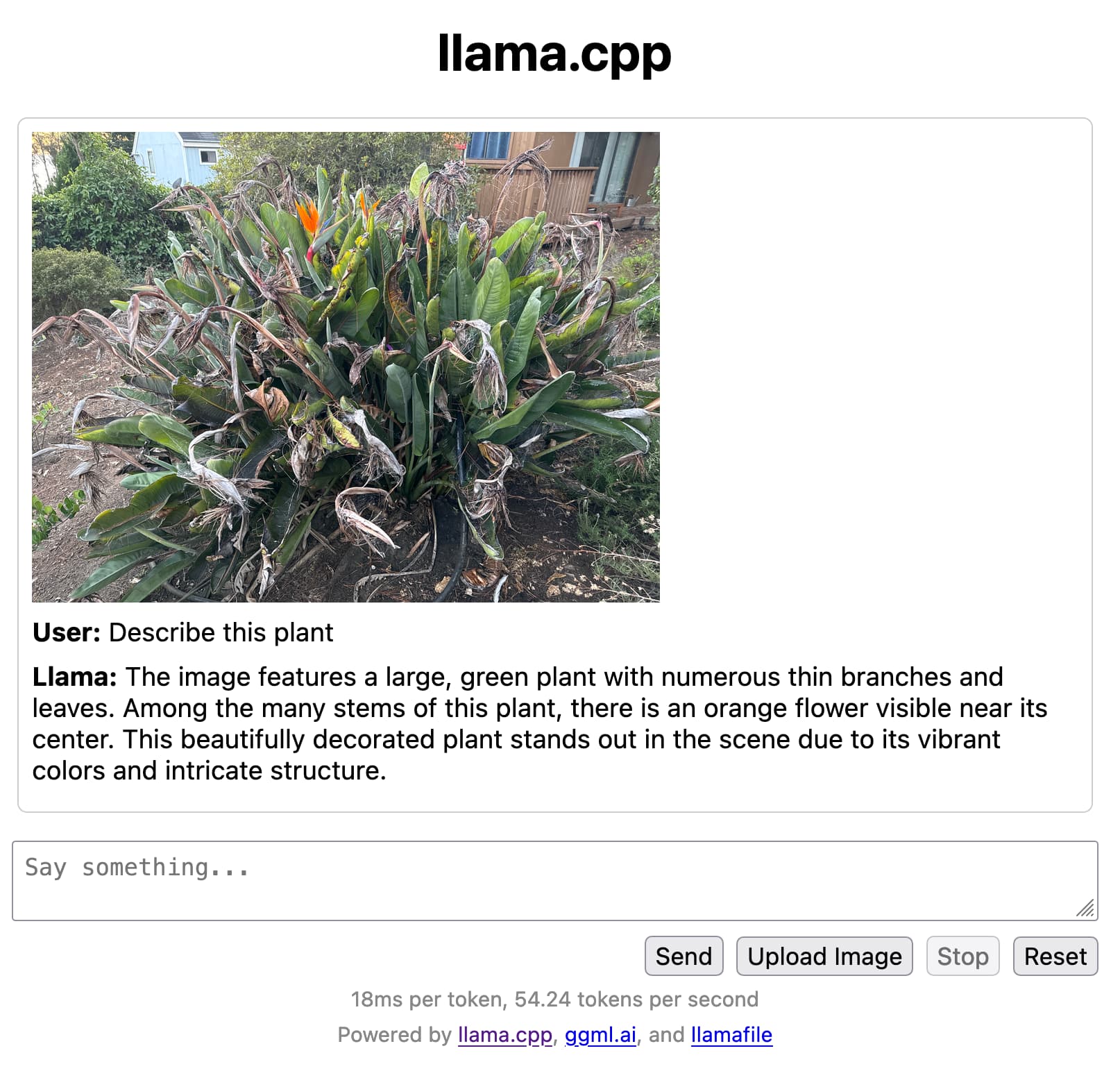
Mozilla’s innovation group and Justine Tunney just released llamafile, and I think it’s now the single best way to get started running Large Language Models (think your own local copy of ChatGPT) on your own computer.
[... 650 words]Thunderbird Is Thriving: Our 2022 Financial Report (via) Astonishing numbers: in 2022 the Thunderbird project received $6,442,704 in donations from 300,000 users. These donations are now supporting 24 staff members. Part of their success is credited to an “in-app donations appeal” that they launched at the end of 2022.
2022
Fastly Compute@Edge JS Runtime (via) Fastly’s JavaScript runtime, designed to run at the edge of their CDN, uses the Mozilla SpiderMonkey JavaScript engine compiled to WebAssembly.
2020
Defining Data Intuition. Ryan T. Harter, Principal Data Scientist at Mozilla defines data intuition as “a resilience to misleading data and analyses”. He also introduces the term “data-stink” as a similar term to “code smell”, where your intuition should lead you to distrust analysis that exhibits certain characteristics without first digging in further. I strongly believe that data reports should include a link the raw methodology and numbers to ensure they can be more easily vetted—so that data-stink can be investigated with the least amount of resistance.
Bedrock: The SQLitening (via) Back in March 2018 www.mozilla.org switched over to running on Django using SQLite! They’re using the same pattern I’ve been exploring with Datasette: their SQLite database is treated as a read-only cache by their frontend servers, and a new SQLite database is built by a separate process and fetched onto the frontend machines every five minutes by a scheduled task. They have a healthcheck page which shows the latest version of the database and when it was fetched, and even lets you download the 25MB SQLite database directly (I’ve been exploring it using Datasette).
2019
Get your own Pocket OAuth token (via) I hate it when APIs make you jump through extensive hoops just to get an access token for pulling data directly from your own personal account. I’ve been playing with the Pocket API today and it has a pretty complex OAuth flow, so I built a tiny Flask app on Glitch which helps go through the steps to get an API token for your own personal Pocket account.
Pyodide: Bringing the scientific Python stack to the browser (via) More fun with WebAssembly: Pyodide attempts (and mostly succeeds) to bring the full Python data stack to the browser: CPython, NumPy, Pandas, Scipy, and Matplotlib. Also includes interesting bridge tools for e.g. driving a canvas element from Python. Really interesting project from the Firefox Data Platform team.
Since Mozilla moved on from Firefox OS, its derivatives have shipped on an order of magnitude more devices than during its entire time under Mozilla’s leadership and it has gone on to form the basis of the third largest and fastest growing mobile operating system in the world.
2018
react-jsonschema-form. Exciting library from the Mozilla Services team: given a JSON Schema definition, react-jsonschema-form can produce a cleanly designed React-powered form for adding and editing data that matches that schema. Includes support for adding multiple items in a nested array, re-ordering them, custom form widgets and more.
Mozilla Telemetry: In-depth Data Pipeline (via) Detailed behind-the-scenes look at an extremely sophisticated big data telemetry processing system built using open source tools. Some of this is unsurprising (S3 for storage, Spark and Kafka for streams) but the details are fascinating. They use a custom nginx module for the ingestion endpoint and have a “tee” server written in Lua and OpenResty which lets them route some traffic to alternative backend.
2017
Verified cryptography for Firefox 57 (via) Mozilla just became the first browser vendor to ship a formally verified crypto implementation.
2010
A predictable web of data—the why of YQL. Christian Heilmann is moving from Yahoo! to Mozilla to head up their evangelism team, and has marked the occasion by releasing the first chapter of a proposed book on YQL.
Plugging the CSS History Leak (via) Firefox is fixing the nefarious CSS visited link colour history leak flaw, which currently affects all browsers and allows a malicious site to determine if you have visited a specific site by checking getComputedStyle against a link to that page. It’s an obtrusive but necessary fix—visited link styles will be restricted to colour and border styles (no background images and hence no more checkbox effects since the image request could leak information) and those colours will not be reported via getComputedStyle. I hope other browser vendors follow suit.
Cache Machine: Automatic caching for your Django models. This is the third new ORM caching layer for Django I’ve seen in the past month! Cache Machine was developed for zamboni, the port of addons.mozilla.org to Django. Caching is enabled using a model mixin class (to hook up some post_delete hooks) and a custom caching manager. Invalidation works by maintaining a “flush list” of dependent cache entries for each object—this is currently stored in memcached and hence has potential race conditions, but a comment in the source code suggests that this could be solved by moving to redis.
2009
So’s your facet: Faceted global search for Mozilla Thunderbird. Yes! This is the kind of innovation I’ve been hoping would show up in e-mail clients for years. Faceting is a really natural fit for e-mail.
HTML 5 Parsing. Firefox nightlies include a new parser that implements the HTML5 parsing algorithm (disabled by default), which uses C++ code automatically generated from Henri Sivonen’s Java parser first used in the HTML5 validator.
Codecs for <audio> and <video>. HTML 5 will not be requiring support for specific audio and video codecs—Ian Hickson explains why, in great detail. Short version: Apple won’t implement Theora due to lack of hardware support and an “uncertain patent landscape”, while open source browsers (Chromium and Mozilla) can’t support H.264 due to the cost of the licenses.
Firefox 3.5 for developers. It’s out today, and the feature list is huge. Highlights include HTML 5 drag ’n’ drop, audio and video elements, offline resources, downloadable fonts, text-shadow, CSS transforms with -moz-transform, localStorage, geolocation, web workers, trackpad swipe events, native JSON, cross-site HTTP requests, text API for canvas, defer attribute for the script element and TraceMonkey for better JS performance!
python-spidermonkey. A Python to JavaScript bridge using Mozilla Spidermonkey. Expose Python objects to JavaScript, or execute JavaScript from Python.
Crowbar. Headless Gecko/XULRunner which exposes a web service API for screen scraping using a real browser DOM—just pass it the URL of a page and the URL of a screen scraping JavaScript script (a bit like a Greasemonkey user script) and get back RDF/XML.
2008
Browser Paint Events. The latest Firefox nightlies include a new MozAfterPaint event which fires after a portion of the page has been redrawn and provides co-ordinates of the affected rectangle. John Resig provides a neat bookmarklet that uses the new event to visualise repainting operations.
TraceMonkey. Brendan Eich has been preaching the performance benefits of tracing and JIT for JavaScript on the conference circuit for at least a year, and the results from the first effort to be merged in to Mozilla core are indeed pretty astounding.
Firefox 3’s password remembering. I’m loving Firefox 3, and the way it does password remembering (with a non-modal toolbar so you can tell if your password worked before deciding to save it) is just one of the major improvements. Opera gets this right as well.
Major Update to Prism (via) Mozilla’s site-specific browser tool can now use separate profiles (and hence separate cookie jars) for each instance, making it an excellent tool for protecting yourself against CSRF vulnerabilities in the web applications you rely on.